
 Sample Submission Guidelines
Sample Submission Guidelines
Long Amplicon Analysis (LAA)
CD Genomics provides professional and cost-effective LAA service with sequencing depth ranging from <500 to 10K CCSs per sample to meet your specific research requirements.
The Introduction of Long Amplicon Analysis
Long Amplicon Analysis (LAA) is a molecular biology technique designed for investigating and scrutinizing extended DNA sequences. This strategy primarily amplifies long fragments of genomic DNA through the Polymerase Chain Reaction (PCR) before subsequent sequencing and data interpretation. This method has significant applications in genomics, evolutionary biology, disease research, along with other fields necessitating research on complex gene structure and variations.
Based on PacBio Circular Consensus Sequences (CCSs), polymerase could copy the same DNA region for several times, which generates high-fidelity, long reads (>99.9% single-molecule read accuracy). Long Amplicon Analysis (LAA) using Single Molecule, Real-Time (SMRT) Sequencing and the Sequel System produces highly accurate and phased CCSs from long amplicons.
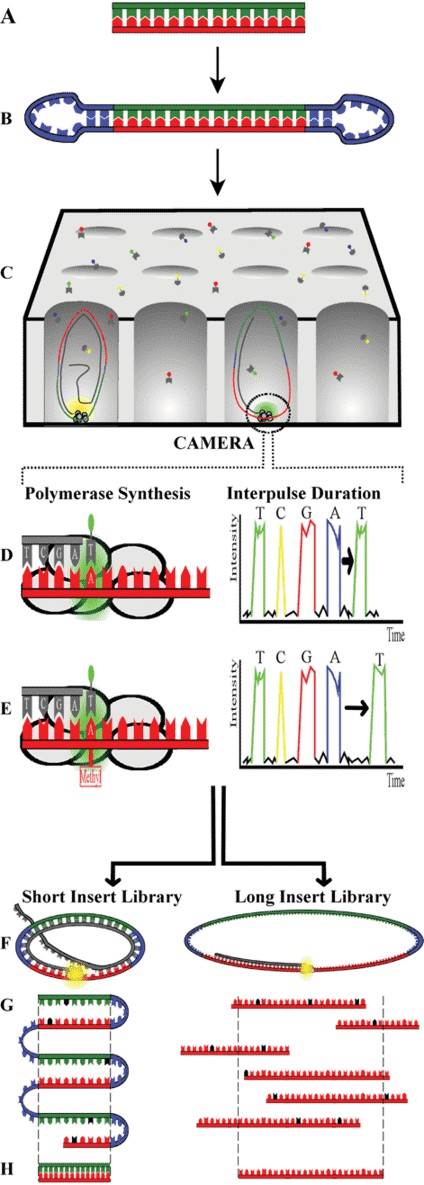 Figure 1. Overview of SMRT Sequencing Technology. (Simon Ardui, et al., 2018)
Figure 1. Overview of SMRT Sequencing Technology. (Simon Ardui, et al., 2018)
Compared to the short-read sequencing platforms, PacBio's long read sequencing makes it is straightforward to sequence amplicons or captured fragments ranging in size from several hundred base pairs up to 10 Kb. These long sequences are very useful for visualization of variants including SNPs, CNVs, and other structural variants that typically do not require assembly.
What are the Advantages of Long Amplicon Analysis
- High Accuracy: Owing to the use of high-fidelity polymerases, Long Amplicon Analysis reduces errors during the amplification process, enhancing the reliability of results.
- Complex Region Resolution: LAA can cover and elucidate complex and repetitive regions within the genome, providing a more comprehensive set of genomic information.
- Wide Applicability: The technique is not only applicable for nuclear genomes but also useful for the analysis of various DNA types, including mitochondrial DNA and chloroplast DNA.
- High Detection Sensitivity: Long Amplicon Analysis can identify and detect large insertions/deletions, inversions, and translocations, thereby increasing the sensitivity of detection for complex genome variations.
- High Haplotypic Resolution: Long-read sequencing can identify and differentiate between various haplotypes from the same individual within a single amplicon, delivering detailed information about haplotype structure and variations.
- Full Gene Length Coverage: For mutations involving multiple exons or entire genes, LAA can cover whole gene regions, ensuring no key mutations are missed.
- Simplified Assembly Process: The long-read capability covers larger genomic regions, reducing mismatches and redundancies during the assembly process, making the assembly results precise and reliable.
What are the Application of Long Amplicon Analysis
- Full-length 16S/18S/ITS gene sequencing
- Full-length HLA Typing
- Alternative haplotyping
- De novo assembly of targeted gene
- Custom amplicon sequencing
Long Amplicon Analysis Workflow

Service Specification
Sample Requirements
|
|
 |
Sequencing
|
 |
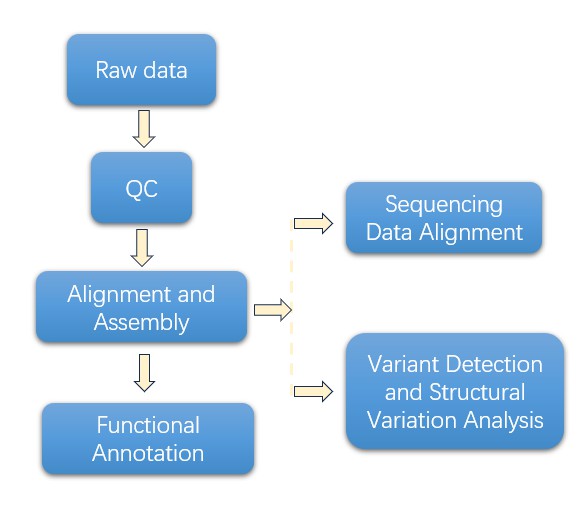
Bioinformatics Analysis
For full-length 16S/18S/ITS gene sequencing:
|
Analysis Pipeline
Deliverables
- The original sequencing data
- Experimental results
- Data analysis report
- Details in Long Amplicon Analysis for your writing (customization)
References:
- Simon Ardui, et al. (2018) Single molecule real-time (SMRT) sequencing comes of age: applications and utilities for medical diagnostics. Nucleic Acids Research. 46(5) 2159–2168.
- Joshua P. Earl, et al. (2018) Species-level bacterial community profiling of the healthy sinonasal microbiome using Pacific Biosciences sequencing of full- length 16S rRNA genes. Microbiome. 6.
- Henk P.J. Buermans, et al. (2017) Flexible and Scalable Full-Length CYP2D6 Long Amplicon PacBio Sequencing. Human Mutation. 38(3) 310–316.
- Frans, Glynis, et al. (2018) Conventional and single-molecule targeted sequencing method for specific variant detection in IKBKG while bypassing the IKBKGP1 pseudogene. The Journal of Molecular Diagnostics 20(2): 195-202.
Demo Results
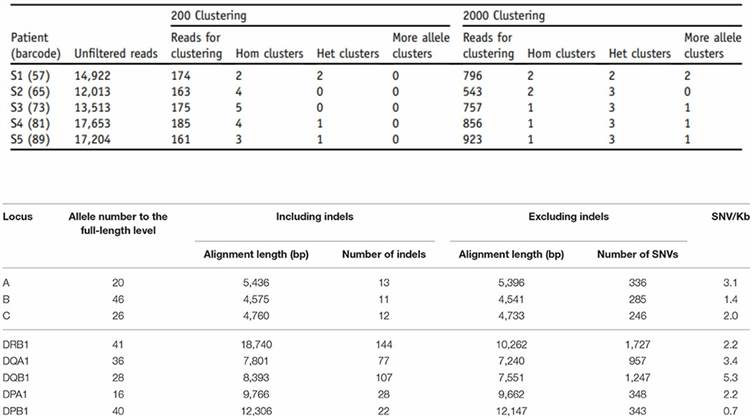 (Frans et al., 2018)
(Frans et al., 2018)
Long Amplicon Analysis (LAA) FAQs
1. What are the main application areas of Long Amplicon Analysis?
Long Amplicon Analysis finds extensive application in an array of research areas, which include:
- Studies on Genomic Structural Variations: It is employed for analyzing intricate variations encompassing significant insertions, deletions, inversions, and repeated sequences.
- Research on Genetic Diseases: This tool aids in the identification of complex mutations that involve elongated genomic regions associated with clinical diagnosis.
- Studies on Evolution and Phylogeny: Long Amplicon Analysis allows exploration of genetic variations between species, thereby shedding light on evolutionary relationships.
- Research on Microbial Diversity: It is used to investigate the structure of the whole genome of microbial communities in various environmental samples.
2. What is the basic workflow of Long Amplicon Analysis?
The core processes that underpin Long Amplicon Analysis commence with DNA extraction and cleansing. The operation entails isolating optimum quality DNA from the given samples. This is followed by a PCR amplification process where specific primers are used in conjunction with high-fidelity polymerases to intensify target segments.
Subsequently, the amplicon purification process takes place, in which residual unamplified DNA and primer dimers are eliminated. This leads to the step of library preparation and a quality control check. Here, libraries compatible with sequencing platforms are prepared and a rigorous quality check is conducted to ensure their suitability for subsequent procedures.
High-throughput sequencing is the next key stage which makes use of platforms like PacBio and Oxford Nanopore adept for long-read sequencing. Following the sequencing step, a comprehensive data analysis is performed. This analysis encompasses quality control, alignment, variant detection, and functional annotation.
Before the data is stored and made available for distribution, there is an important stage of result validation and reporting. Key findings are experimentally verified, and comprehensive analysis reports are generated. As a concluding step, the data is securely stored in databases, following which it is made accessible for sharing in line with the research requirements.
3. What are the commonly used tools in Long Amplicon Analysis data analysis?
Tools used in data analysis include:
Quality control: FastQC, Trimmomatic, Cutadapt.
Alignment and assembly: BWA, Bowtie2, Minimap2, Canu, Flye.
Variant detection: GATK, FreeBayes, Manta, LUMPY.
Functional annotation: ANNOVAR, SnpEff.
4. How to ensure the accuracy and reliability of Long Amplicon Analysis results?
Several methodological protocols can be put in place to bolster accuracy and reliability, such as:
- DNA Extraction and Purification: The implementation of sophisticated kits coupled with meticulous procedure execution can facilitate high-quality DNA extraction and purification.
- PCR Conditions Optimization: Fine-tuning specific conditions within the polymerase chain reaction (PCR) process, such as annealing temperature and extension time, can help secure efficient segment amplification.
- High-Fidelity Polymerase Utilization: The application of high-fidelity polymerases plays an important part in minimizing chances of amplification discrepancies.
- Attentive Quality Control: Stringent quality control measures should be observed at critical junctions during the sequencing and data analysis phases.
- Experimental Validation: Pivotal results should be validated experimentally. This could involve methods such as Sanger sequencing or quantitative PCR (qPCR).
Long Amplicon Analysis (LAA) Case Studies
Defining Blood Group Gene Reference Alleles by Long-Read Sequencing: Proof of Concept in the ACKR1 Gene Encoding the Duffy Antigens
Journal: Transfusion medicine and hemotherapy
Impact factor: 2.283
Published: December 11, 2019
Background
Within the burgeoning field of blood group genomics, defining and redefining reference gene or allele sequences for various blood group genes represent significant objectives, both for diagnostic applications and scientific explorations. Given the emergence of innovative, powerful sequencing technologies, we endeavored to investigate the variability of the three most prominent alleles of ACKR1 - the gene encoding clinically critical Duffy antigens - at the haplotype level, employing a long-read sequencing methodology.
Methods
- Genomic DNA (gDNA) samples
- Blood samples
- Genomic DNA extraction
- LR-PCR amplification
- Library preparation
- SMRT sequencing
- Sequel System
- Data quality control
- Long Amplicon Analysis (LAA) module
- Variant calling
Results
The authors obtained high-quality sequencing reads for the 162 alleles (accuracy >0.999). A total of twenty-two nucleotide variations were identified, which are reported in reputable databases. These variations defined 19 haplotypes: comprised of four in 46 ACKR1*01, eight in 63 ACKR1*02, and seven in 53 ACKR1*02N.01 alleles respectively.
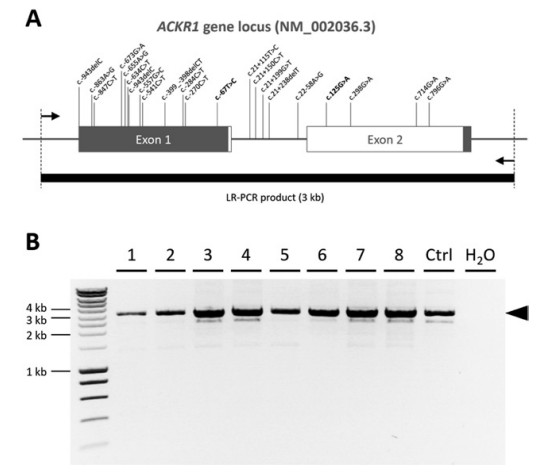 Fig. 1. Long-range PCR (LR-PCR) amplification of the whole ACKR1 gene locus.
Fig. 1. Long-range PCR (LR-PCR) amplification of the whole ACKR1 gene locus.
Table 1. ACKR1 variants and haplotypes identified by long-read sequencing
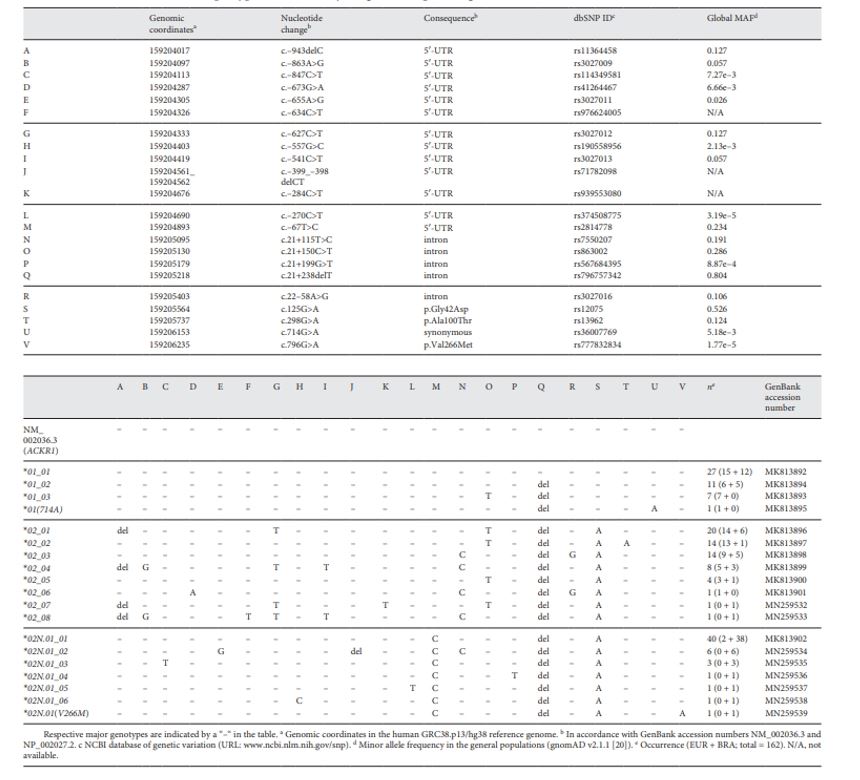
Conclusion
Accordingly, a cadre of specific reference alleles has been established, utilizing third-generation sequencing technology, which offers a longitudinal thorough exploration of gene loci stretching across numerous thousand base pairs. This novel technique complements second-generation or short-read sequencing techniques, proving to be critically instrumental in deciphering novel, rare, and null alleles.
Reference:
- Fichou, Y., Fichou, Y., Berlivet, I., Richard, G., et al. Defining blood group gene reference alleles by long-read sequencing: proof of concept in the ACKR1 gene encoding the duffy antigens. Transfusion medicine and hemotherapy, 2020, 47(1): 23-32.
Related Publications
Here are some publications that have been successfully published using our services or other related services:
Bacterial communities of Cassiopea in the Florida Keys share major bacterial taxa with coral microbiomes
Journal: bioRxiv
Year: 2024
Production of a Bacteriocin Like Protein PEG 446 from Clostridium tyrobutyricum NRRL B-67062
Journal: Probiotics and Antimicrobial Proteins
Year: 2024
Untangling the Role of Pathobionts from Bacteroides Species in Inflammatory Bowel Diseases
Journal: bioRxiv
Year: 2023
A chromosome-level genome resource for studying virulence mechanisms and evolution of the coffee rust pathogen Hemileia vastatrix
Journal: bioRxiv
Year: 2022
Streptomyces buecherae sp. nov., an actinomycete isolated from multiple bat species
Journal: Antonie Van Leeuwenhoek
Year: 2020
See more articles published by our clients.


