
 Sample Submission Guidelines
Sample Submission Guidelines
Long-Read Sequencing Data Analysis Service: Advancing Genomic Research with CD Genomics
Introduction
The era of genomics has witnessed remarkable advancements in sequencing technologies, enabling researchers to delve deeper into the complexities of the genome. One such breakthrough is the advent of long-read sequencing, which offers unprecedented advantages in capturing structural variations, alternative splicing, and gene isoform expression. CD Genomics, a leading company in the field of genomics, proudly presents its cutting-edge Long-Read Sequencing (LRS) Data Analysis Service.
Bioinformatics Analysis of Long-Read Sequencing Data
Long-read sequencing (nanopore sequencing and the single-molecule real-time (SMRT) sequencinggenerates) extended sequencing reads, revolutionizing our ability to explore the intricate landscape of the genome. However, the analysis of these extensive datasets poses unique challenges. CD Genomics, with its extensive expertise in bioinformatics analysis, employs state-of-the-art computational tools and pipelines to overcome these challenges and extract valuable insights from long-read sequencing data.
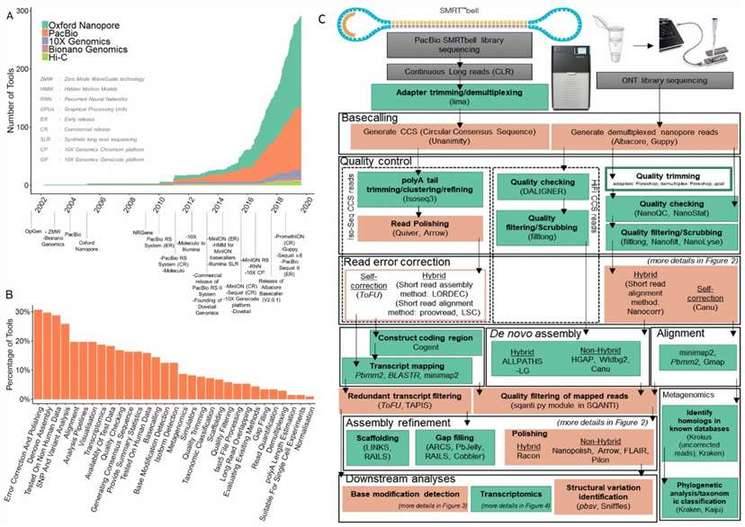 Overview of long-read analysis tools and pipelines.
Overview of long-read analysis tools and pipelines.
Quality Control and Error Correction
High-quality data is vital for accurate downstream analysis. CD Genomics employs rigorous quality control measures to assess the integrity of long-read sequencing data. Through meticulous quality trimming and filtering, we ensure the removal of artifacts and low-quality reads, enhancing the reliability of subsequent analyses.
Gene/Gene Isoform Expression
Long-read sequencing enables the comprehensive analysis of gene expression and isoform diversity. CD Genomics employs sophisticated algorithms and tools to quantify gene and isoform expression levels accurately. This facilitates the identification of differentially expressed genes and isoforms across various conditions, shedding light on crucial biological processes and regulatory mechanisms.
Novel Gene Discovery and Full-Length Isoform Identification
Uncovering novel genes and full-length isoforms is pivotal for expanding our understanding of the genome. CD Genomics leverages advanced transcriptome assembly methods to reconstruct complete gene structures and identify novel genes and isoforms with high precision. By leveraging the power of long-read sequencing, our service facilitates the discovery of previously unannotated genes and transcript variants.
De Novo Fusion Gene Detection and Fusion Isoform Expression Profiles
Fusion genes, formed by genomic rearrangements, play a crucial role in cancer and other diseases. CD Genomics employs specialized algorithms and pipelines to detect fusion genes and determine their expression profiles. Through in-depth analysis of fusion isoforms, our service helps unravel the underlying mechanisms of disease development and progression.
Allele-Specific Expression and Haplotyping
Understanding allele-specific expression and haplotypes is vital for unraveling the complexities of genetic variations. CD Genomics offers precise analysis of long-read sequencing data to unravel allele-specific expression patterns and haplotypes. This information provides insights into the regulation of gene expression and the impact of genetic variations on phenotypic traits.
De Novo Genome Assembly
De novo genome assembly is a crucial step in deciphering complex genomes, particularly in non-model organisms. CD Genomics utilizes cutting-edge assembly algorithms optimized for long-read sequencing data to reconstruct high-quality genome assemblies. This allows for the identification of structural variations, gene annotations, and genome-wide analyses with exceptional accuracy.
De Novo Transcriptome Assembly
CD Genomics provides comprehensive de novo transcriptome assembly services using long-read sequencing data. Leveraging advanced algorithms, we reconstruct full-length transcript isoforms, uncover alternative splicing events, and provide precise gene annotations. This empowers researchers to gain deeper insights into the transcriptomic landscape and decipher the complexities of gene regulation.
Methylation Calling, Nucleosome Positioning, and Chromatin Accessibility
Epigenetic modifications play a pivotal role in gene regulation and disease development. CD Genomics offers comprehensive analysis of long-read sequencing data to identify DNA methylation patterns, determine nucleosome positioningand chromatin accessibility. By analyzing long-read sequencing data, CD Genomics can accurately map nucleosome positions and assess chromatin accessibility across the genome. This information provides valuable insights into gene regulation, chromatin structure, and the impact of epigenetic modifications on cellular processes.
Advantages of CD Genomics' Long-Read Sequencing Data Analysis Service
Unparalleled Accuracy and Precision: Our experienced team ensures the highest standards of data analysis, delivering accurate and precise results.
Customized Data Analysis Solutions: We tailor our analysis pipelines to meet your specific research goals, providing customized solutions for your unique project requirements.
Cutting-Edge Bioinformatics Pipelines: We utilize state-of-the-art bioinformatics pipelines optimized for long-read sequencing data analysis, incorporating the latest algorithms and tools.
Comprehensive Reporting and Interpretation: Our service includes detailed analysis reports and clear interpretations of the findings, enabling you to derive meaningful insights from the data.
Efficient Turnaround Time: We prioritize timely results without compromising on quality, ensuring you receive your analysis results within the agreed-upon timelines.
Confidentiality and Data Security: We maintain strict data management protocols and employ robust security measures to ensure the confidentiality and integrity of your sequencing data.
By choosing CD Genomics' Long-Read Sequencing Data Analysis Service, you gain access to accurate and customized analysis, cutting-edge bioinformatics pipelines, comprehensive reporting, efficient turnaround times, and data security, empowering you to advance your genomic research with confidence.


