
 Sample Submission Guidelines
Sample Submission GuidelinesWe use cookies to understand how you use our site and to improve the overall user experience. This includes personalizing content and advertising. Read our Privacy Policy
Accept Cookies

August 26, 2019
Vincent Libis, Niv Antonovsky, Mengyin Zhang, Zhuo Shang, Daniel Montiel, Jeffrey Maniko, Melinda A. Ternei, Paula Y. Calle, Christophe Lemetre, Jeremy G. Owen & Sean F. Brady
Nature Communications volume 10, Article number: 3848 (2019)
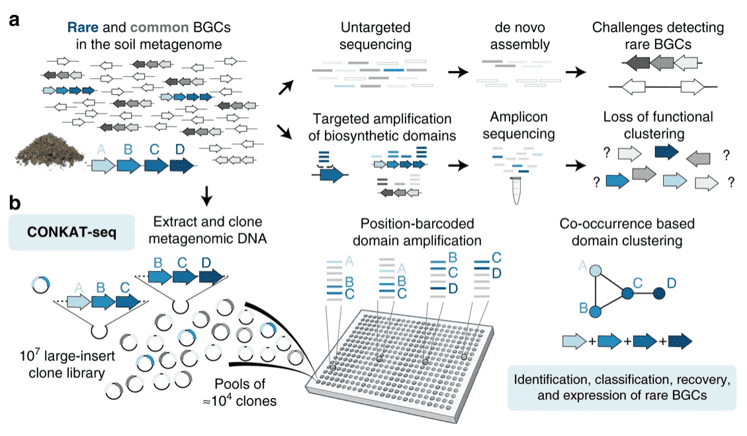 CONKAT-seq enables the exploration of rare biosynthetic gene clusters in complex metagenomes.
CONKAT-seq enables the exploration of rare biosynthetic gene clusters in complex metagenomes.
Abstract
Sequencing of DNA extracted from environmental samples can provide key insights into the biosynthetic potential of uncultured bacteria. However, the high complexity of soil metagenomes, which can contain thousands of bacterial species per gram of soil, imposes significant challenges to explore secondary metabolites potentially produced by rare members of the soil microbiome. Here, we develop a targeted sequencing workflow termed CONKAT-seq (co-occurrence network analysis of targeted sequences) that detects physically clustered biosynthetic domains, a hallmark of bacterial secondary metabolism. Following targeted amplification of conserved biosynthetic domains in a highly partitioned metagenomic library, CONKAT-seq evaluates amplicon co-occurrence patterns across library subpools to identify chromosomally clustered domains. We show that a single soil sample can contain more than a thousand uncharacterized biosynthetic gene clusters, most of which originate from low frequency genomes which are practically inaccessible through untargeted sequencing. CONKAT-seq allows scalable exploration of largely untapped biosynthetic diversity across multiple soils, and can guide the discovery of novel secondary metabolites from rare members of the soil microbiome.
More info at: https://www.nature.com/articles/s41467-019-12079-8


