
 Sample Submission Guidelines
Sample Submission Guidelines
From Data to Discovery: Advanced Applications of Genotyping by Sequencing
Genotyping by Sequencing (GBS) is revolutionizing genetic research by offering a cost-effective yet high-resolution method for detecting genome-wide markers, thereby addressing the constraints associated with traditional techniques. This article delves into the fundamental principles, diverse applications, and prospective trajectories of GBS. It highlights its significant contributions across various domains, including functional genomics, plant breeding, biodiversity conservation, and the advent of novel bioinformatics solutions. For those keen on exploring genetic variation, expediting crop improvement, or leveraging genomic data to tackle ecological challenges, this comprehensive review serves as a gateway to the groundbreaking advancements ushered in by GBS and underscores its increasingly pivotal role in the realm of contemporary science.
GBS in Genetics
Genotyping by Sequencing is revolutionizing genetic research by overcoming the limitations of traditional genome analysis methods. Conventional techniques often face challenges such as high costs, low throughput, and limited resolution, making it difficult to conduct in-depth analysis on a large scale. GBS addresses these issues by simplifying library preparation and leveraging high-throughput sequencing, enabling cost-effective, high-density marker detection across complex genomes. Its core advantage lies in its ability to extend beyond model organisms, making it directly applicable to species without reference genomes. This is achieved through a unique enzyme-based strategy—using restriction enzymes to fragment the genome and selectively capture functional regions, thereby reducing data volume while preserving key genetic variations.
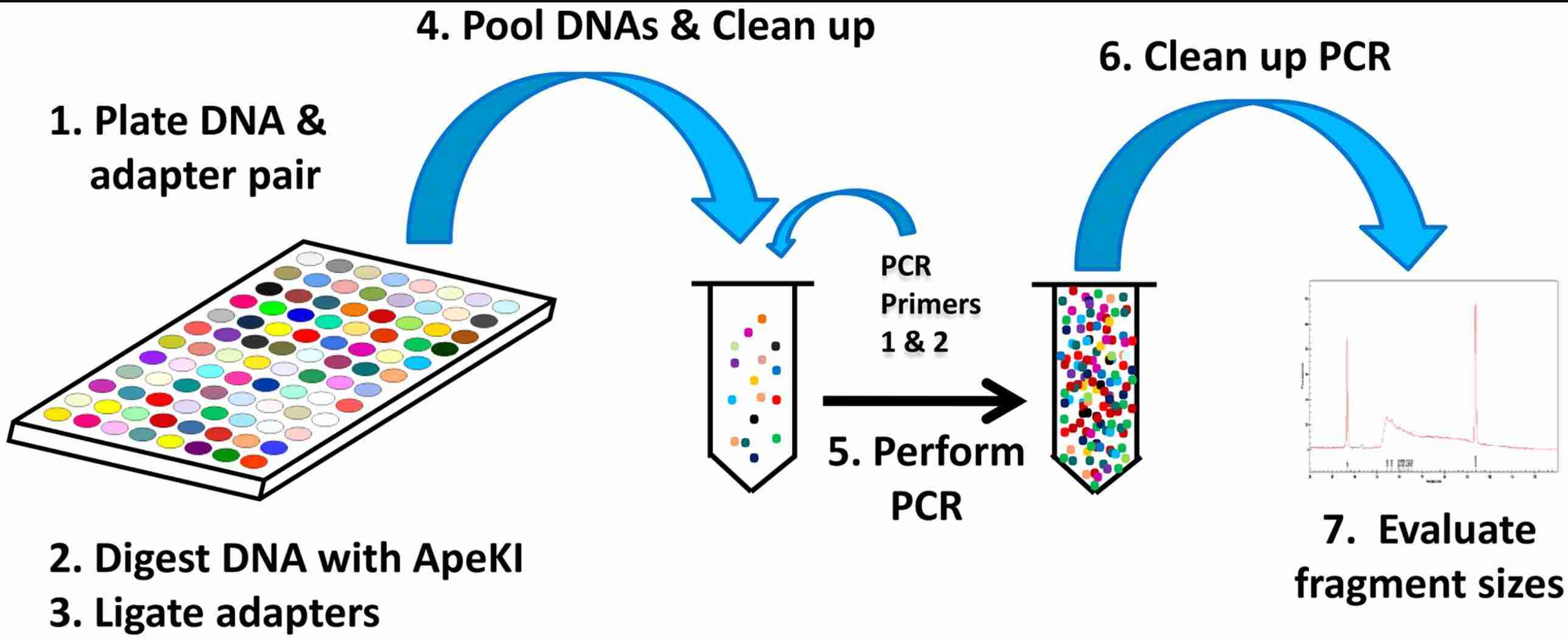 Steps in Genotyping-by-Sequencing (GBS) library construction (Elshire et al., 2011).
Steps in Genotyping-by-Sequencing (GBS) library construction (Elshire et al., 2011).
In functional genomics, GBS is increasingly used to uncover the complex relationships between genotypes and phenotypes. For instance, by integrating methylation-sensitive enzyme digestion, researchers can simultaneously obtain genetic variation and epigenetic modification data in a single experiment. This dual-dimensional analysis not only elucidates the regulatory role of DNA methylation on gene expression but also reveals the transgenerational inheritance of epigenetic memory under environmental stress. Moreover, GBS's innovative applications in host-microbe interaction studies provide molecular insights into the co-evolution of gut microbiota and host metabolism. These methodological breakthroughs signify a shift in genetic research from single-variant detection to the systematic analysis of complex biological networks.
The advancement of GBS is heavily reliant on the evolution of bioinformatics algorithms. The vast data generated by GBS demands more sophisticated processes for genotype imputation and variant annotation. Machine learning-based imputation algorithms, which integrate population genetic structure information, have significantly improved the accuracy of rare variant detection. Additionally, the introduction of long-read sequencing technologies is addressing the limitations of short-read GBS in detecting structural variations, enabling precise identification of large-scale genomic rearrangements such as inversions and translocations. This multi-technology fusion strategy not only broadens the application scope of GBS but also drives the transition of genomics from static description to dynamic mechanistic studies.
GBS in plant breeding and crop improvement
In modern agriculture, GBS is transforming the entire process of crop genetic improvement. A key breakthrough is the reduction of whole-genome marker detection costs to one-tenth of traditional methods, making genomic selection (GS) a widely accessible breeding tool. By constructing genome-wide single nucleotide polymorphism (SNP) maps, breeders can quantify the genetic distribution of target traits, optimizing parental selection strategies. This data-driven approach significantly shortens the breeding cycle for trait fixation, particularly in the improvement of polygenic quantitative traits.
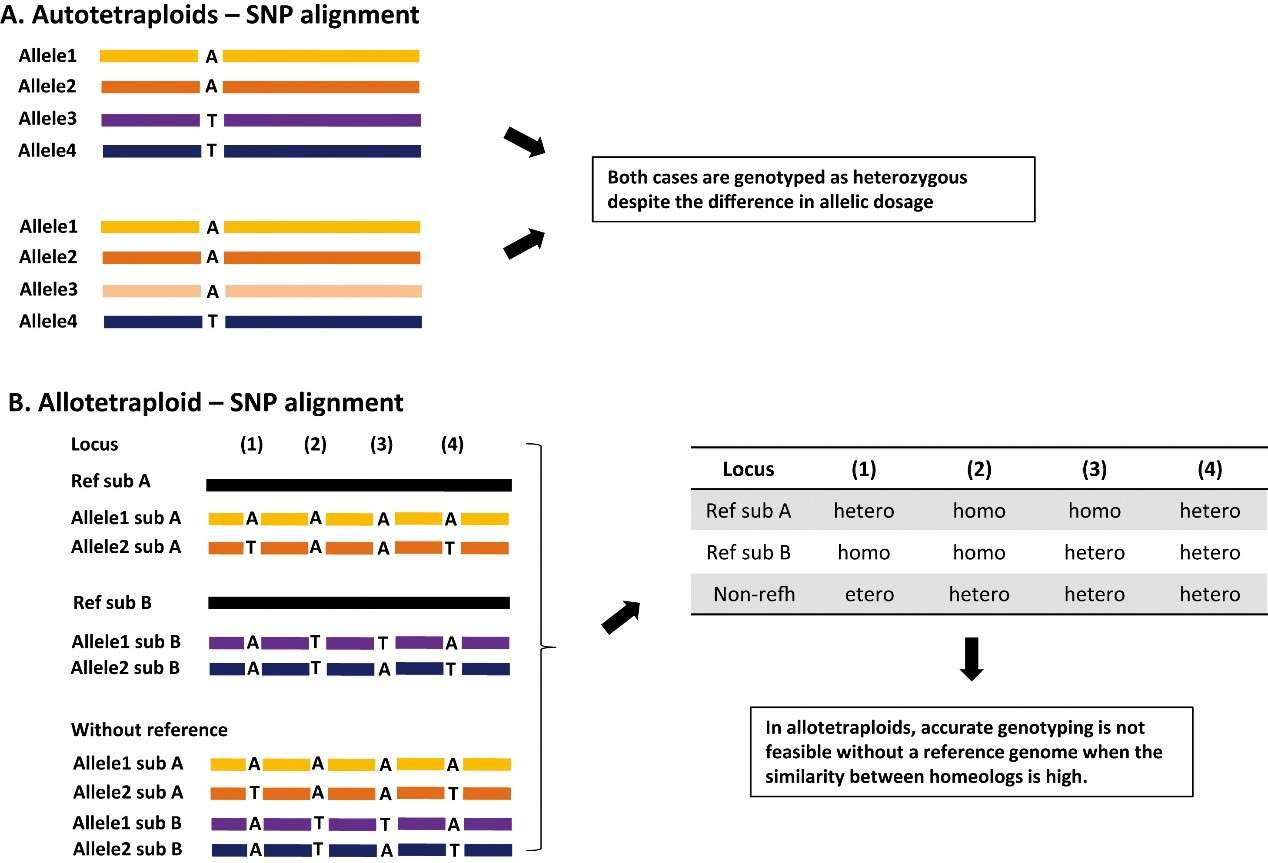 Complications of GBS application in autotetraploid species lacking a reference genome (Kim et al., 2016).
Complications of GBS application in autotetraploid species lacking a reference genome (Kim et al., 2016).
GBS has also revolutionized stress resistance breeding. Traditional methods relying on phenotypic screening are often inefficient and unpredictable due to environmental heterogeneity and genotype-environment interactions. GBS, however, can identify conserved genetic modules related to stress resistance, enabling cross-species recognition of functionally homologous genes. For example, clusters of osmotic regulation genes discovered in grasses have been successfully transferred to other crops using gene editing, enhancing their drought resistance. This "natural variation mining-functional verification-design breeding" cycle highlights GBS's pivotal role in germplasm innovation.
Looking ahead, GBS is driving the personalization of crop breeding. By integrating metabolomic and phenotypic data, researchers can develop predictive models from genotypes to end-product quality traits. These models not only guide the targeted improvement of specific flavor compounds or nutritional components but also predict the stability of varieties in different ecological environments. This end-to-end solution marks a fundamental shift from experience-driven to model-driven crop breeding, providing a technological foundation to address food security challenges in the face of climate change.
Ecological genomics and conservation efforts
In biodiversity conservation, GBS is expanding the horizons of traditional conservation genetics. Previous studies relying on mitochondrial DNA or microsatellite markers could only reflect neutral evolutionary histories. GBS, however, offers a genome-wide perspective, allowing researchers to simultaneously track adaptive evolutionary signals. This dual-track analysis is crucial for assessing the evolutionary potential of endangered species—populations with high genomic heterozygosity may still lose critical functional gene diversity, rendering them unable to cope with environmental changes.
GBS is also transforming strategies for invasive species control. High-density SNP maps can precisely dissect the spatiotemporal dynamics of invasion routes and identify genomic regions associated with enhanced invasive capabilities. This information provides molecular targets for developing targeted gene silencing technologies, shifting ecological control from broad-spectrum eradication to precise intervention. For example, biocontrol agents designed for specific genotypes can effectively suppress invasive populations without affecting native species.
In the context of global climate change, GBS is increasingly used to predict adaptive evolution. By comparing historical samples with contemporary populations, researchers can quantify the impact of selective pressures on allele frequency. Integrated with ecological niche models, this data can predict the adaptive trajectories of specific genotypes under future climate scenarios, providing scientific support for the dynamic management of protected areas. This interdisciplinary practice of embedding genomic data into ecosystem modeling signifies a strategic upgrade in conservation biology from passive monitoring to active intervention.
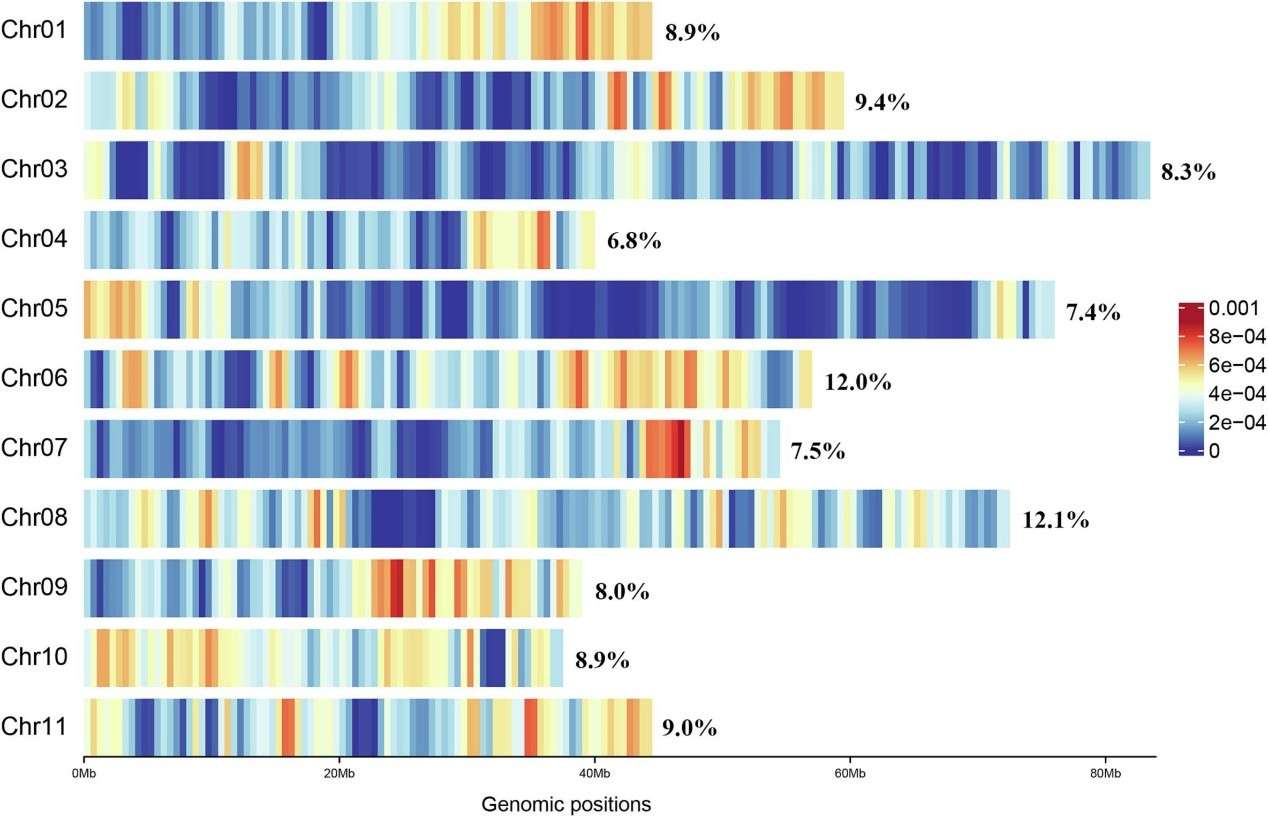 Genome-wide single-nucleotide polymorphism (SNP) distributions over the 11 Eucalyptus grandis chromosomes detected using GBS (Wang et al., 2023).
Genome-wide single-nucleotide polymorphism (SNP) distributions over the 11 Eucalyptus grandis chromosomes detected using GBS (Wang et al., 2023).
Services you may interested in
Learn More
GBS Data Analysis
The journey from raw sequencing data to actionable biological insights in Genotyping-by-Sequencing requires meticulous methodological rigor, balancing computational efficiency with analytical precision. Below, we outline critical steps and innovations that address both technical and biological complexities inherent to modern GBS workflows.
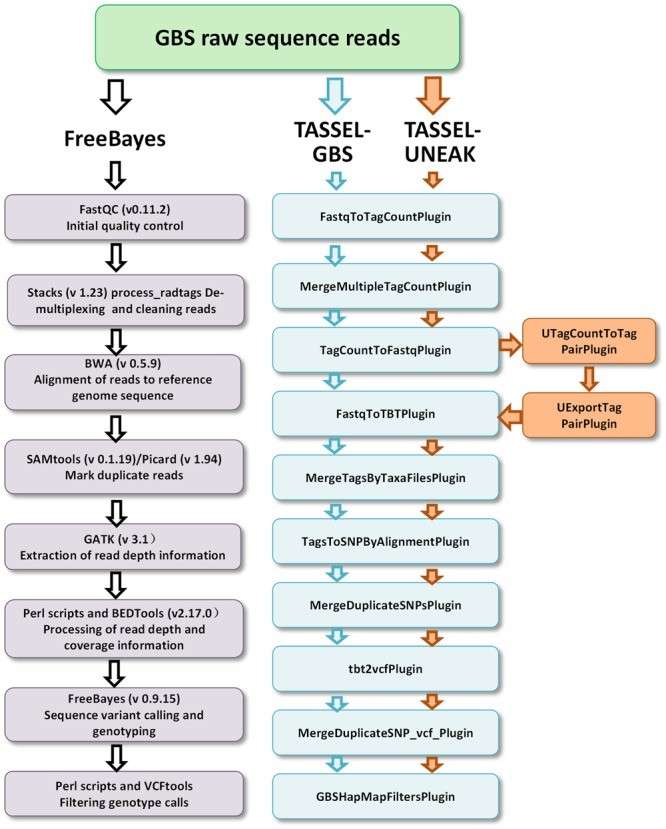 Three GBS pipelines including FreeBayes (left), TASSEL-GBS (medium), and TASSEL-UNEAK (medium and right) used for genotype calling (Yu et al., 2017).
Three GBS pipelines including FreeBayes (left), TASSEL-GBS (medium), and TASSEL-UNEAK (medium and right) used for genotype calling (Yu et al., 2017).
Preprocessing and quality control
The primary challenge in GBS data analysis lies in the standardized processing of massive raw datasets. Modern sequencing platforms generate terabytes of data, demanding both computational resources and optimized workflows. Cloud-based solutions, with their elastic computing nodes and distributed storage architectures, enable parallelized and automated data processing. This framework not only dynamically adjusts resource allocation to accommodate data fluctuations but also ensures reproducibility through containerized technologies like Docker. Key preprocessing steps include deduplication of raw sequences, adapter identification and removal, and dynamic trimming based on sequencing quality scores—all aimed at preserving true biological signals while minimizing technical noise.
Deep quality control involves distinguishing biological variation from technical bias. Traditional threshold-based filtering methods, such as Phred quality score screening, can eliminate low-quality sites but may also inadvertently discard rare true variants. To address this, deep learning-based noise recognition models are becoming mainstream. These models, trained on vast datasets, can automatically identify and correct systematic errors such as sequencing biases and PCR duplicates. Importantly, quality control is not a one-way filtering process but should incorporate feedback mechanisms to iteratively optimize parameters based on specific research goals.
Variant calling and population structure analysis
Variant identification is the core of GBS analysis, with its accuracy directly impacting subsequent biological conclusions. In outcrossing species like many trees, haplotype resolution is particularly critical due to their high heterozygosity. Short-read data often cannot directly assemble complete haplotypes. Graph-based assembly algorithms, such as Haplotype Graph, integrate read information from all individuals in a population to reconstruct the historical trajectories of complex recombination events. This population-level haplotype inference offers new insights into the impact of mating systems on genetic diversity.
Linking genetic variation to environmental factors represents a leap in GBS applications from descriptive statistics to mechanistic exploration. Custom bioinformatics pipelines can couple SNP data with multidimensional environmental datasets, such as temperature gradients and soil composition distributions. The core challenge is to establish statistical models that distinguish environmental selection signals from neutral evolutionary processes. Bayesian-based gradient forest analysis quantifies the explanatory power of environmental variables on allele frequency, identifying adaptive sites driven by natural selection. Such analyses not only reveal species' responses to environmental changes but also predict genetic adaptation trajectories under future climate scenarios.
Future Trends in Genotyping by Sequencing
Contemporary genotyping by sequencing (GBS) methodologies are undergoing a paradigm shift, driven by the dual imperatives of overcoming analytical constraints in hyperdiverse ecosystems and addressing ethical complexities in data stewardship. Traditional reference genome-dependent approaches, while foundational, exhibit critical limitations when applied to systems such as coral reef metagenomes or fungal symbiont networks, where structural variations and allelic diversity often evade detection. K-mer spectrum analysis emerges as a pivotal reference-free alternative, leveraging frequency distribution patterns to directly infer population-level polymorphisms without genome assembly. This strategy circumvents reference bias and reveals cryptic structural variations, yet faces inherent computational bottlenecks due to exponential scaling of k-mer combinatorial space. Recent advances integrate Bloom Filter-based compression with distributed computing architectures (e.g., Apache Spark), enabling efficient processing of petascale k-mer datasets—a breakthrough that reduces SNP detection latency by three orders of magnitude while preserving topological accuracy in variant calling.
Concurrently, the ethical dimensions of GBS research demand innovative governance frameworks. Indigenous biocultural resources necessitate protocols that harmonize open science principles with data sovereignty, requiring blockchain-enabled smart contracts to enforce immutable audit trails for traditional knowledge access. This technological-ethical synergy extends to emergent field applications: nanopore sequencing coupled with microfluidic edge-computing platforms now enables portable, real-time genotyping workflows. Such systems dissolve the spatial-temporal barriers of conventional laboratory pipelines, allowing in situ DNA extraction, adaptive library preparation (featuring dynamic enzymatic optimization via real-time DNA quality feedback), and embedded base-calling via energy-efficient neural networks (<50mW/sample). These innovations collapse genotype-to-phenotype association timelines from months to hours, revolutionizing crisis responses in biodiversity conservation and phytopathological emergencies.
The confluence of these advancements positions GBS as a multidimensional decision-support tool, characterized by three evolutionary trajectories: (1) context-aware sampling protocols with autonomous parameter calibration, (2) temporal compression of evolutionary signal detection through distributed edge analytics, and (3) decentralized research networks powered by blockchain-verified data commons. By interweaving computational scalability with ethical accountability, modern GBS transcends its analytical origins to become a responsive ecosystem stewardship instrument—one uniquely capable of mapping molecular diversity dynamics to ecological resilience in real time, thus addressing urgent conservation challenges in the Anthropocene epoch.
Summary: the Impact of GBS
The full potential of GBS technology hinges on the construction of interdisciplinary knowledge networks. The deep collaboration of genomicists, ecological modelers, and data scientists is giving rise to a new generation of analytical frameworks This integration poses fundamental methodological challenges: how to balance the granularity of genomic data with the large-scale abstraction needs of ecological models? A potential solution lies in developing multi-level modeling architectures that retain critical genetic details while maintaining computational feasibility.
The acceleration of technology democratization is evident in the ecosystem development of open-source tools. Low-resource research institutions can customize their research workflows using modular GBS analysis platforms like GBS-Cube, which integrate cloud cost optimization, pre-trained model deployment, and interactive visualization in a unified interface. More revolutionary is the blockchain-enabled distributed knowledge-sharing network, where researchers can securely contribute and access standardized GBS datasets while automatically receiving academic contribution certification through smart contracts. This decentralized scientific collaboration model may reshape the global distribution of research resources.
References:
- Elshire RJ, Glaubitz JC, Sun Q, Poland JA, Kawamoto K, Buckler ES, Mitchell SE. "A robust, simple genotyping-by-sequencing (GBS) approach for high diversity species." PLoS One. 2011 6(5):e19379. https://doi.org/10.1371/journal.pone.0019379
- Kim C, Guo H, Kong W, Chandnani R, Shuang LS, Paterson AH. "Application of genotyping by sequencing technology to a variety of crop breeding programs." Plant Sci. 2016 242:14-22. https://doi.org/10.1016/j.plantsci.2015.04.016
- Wang P, Jia C, Bush D, Zhou C, Weng Q, Li F, Zhao H, Zhang H. "Predicting genetic response to future climate change in Eucalyptus grandis by combining genomic data with climate models." Forest Ecology and Management. 2023 549:121492. https://doi.org/10.1016/j.foreco.2023.121492
- Yu LX, Zheng P, Bhamidimarri S, Liu XP, Main D. "The Impact of Genotyping-by-Sequencing Pipelines on SNP Discovery and Identification of Markers Associated with Verticillium Wilt Resistance in Autotetraploid Alfalfa (Medicago sativa L.)." Front Plant Sci. 2017 8:89. https://doi.org/10.3389/fpls.2017.00089.


