
 Sample Submission Guidelines
Sample Submission Guidelines
Principle of Nanopore Sequencing
Intruction of Nanopore Sequencing
The essence of DNA sequencing lies in the identification of the four nucleotides: adenine (A), thymine (T), cytosine (C), and guanine (G). However, the recognition process is challenging for two primary reasons. First, these bases are incredibly tiny, existing at the nanometre scale. Second, the chemical structures of purine-base pairs and pyrimidine-base pairs are remarkably similar, complicating their differentiation. Ever since the proposition of the DNA double helix structure in 1953, biologists have been relentlessly seeking various methodologies for these four bases' identification.
Current predominant sequencing methodologies include transducing the presence of the four bases into signals such as light, changes in pH levels of the solution, or electrical signals. Distinct bases are discerned based on the differences in their amplified signals. These strategies constitute the mainstay of current mainstream sequencing equipment. Notably, platforms such as Sanger, Illumina, BGIseq, and Pacbio have opted for light signals. Conversely, Ion Torrent utilizes variations in solution pH, with Nanopore favoring electrical signals. The sequencing process not only relies on cutting-edge technologies but also underscores the innovation aspect that is akin to an art form.
The paradigm of Nanopore Sequencing technology traces its nascent stages to the 1990s, and its evolution rests upon three pivotal technological leaps. Initially, the transmission of single DNA molecules through a nanopore was achieved; a feat followed by the adoption of an enzymatic process on the nanopore for sequencing supervision at a single nucleotide resolution. Ultimately, single nucleotide sequencing precision became a reality. These innovative strides collectively bolstered the advance of Nanopore Sequencing technology.
Service you may intersted in
- Nanopore metagenomics sequencing
- Nanopore de novo whole genome requencing
Nanopore Sequencing Principle
Nanopore Sequencing operates on the principle of immersing an artificially synthesized polymer membrane in an ionic solution. This polymer membrane is punctuated with modified transmembrane channel protein structures, also known as nanopore protein or "Reader" proteins. These proteins are integral to nanopore sequencing operation. Given the biological activity of the Reader protein, the chip should be stored in a refrigerator at a temperature ranging from 4-8°C and positioned away from the refrigerator walls to prevent freezing due to lower local temperatures.
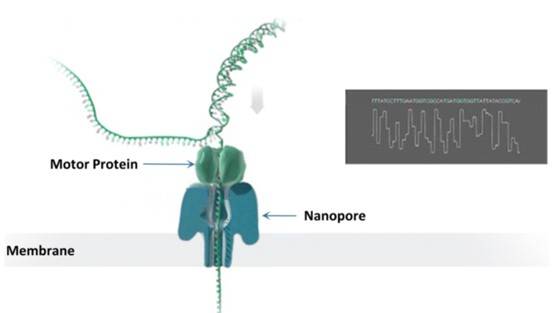 ONT direct DNA sequencing Shangqian (Xie et al., 2021)
ONT direct DNA sequencing Shangqian (Xie et al., 2021)
The protein-embedded artificial membrane structure boasts insoluble properties. Thus, when an external electrical field is applied, electrical current is conveyed solely through the nanopores. Different voltages applied on either side of the membrane create a voltage differential, leading to the unwinding and translocation of DNA under the influence of the motor protein, through the nanopore. At this point, individual nucleotides will induce specific ionic current changes. This membrane exhibits high electrical resistance characteristics. By applying a potential to the membrane immersed in an electrochemical solution, an ionic current can be generated at the nanopore site.
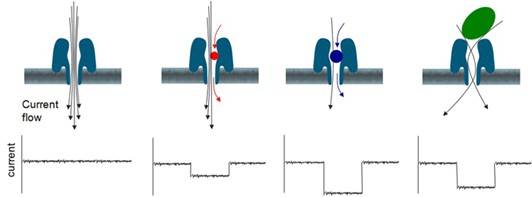 Electric current passes through nanoporer. (Credit: Oxford Nanopore Technologies)
Electric current passes through nanoporer. (Credit: Oxford Nanopore Technologies)
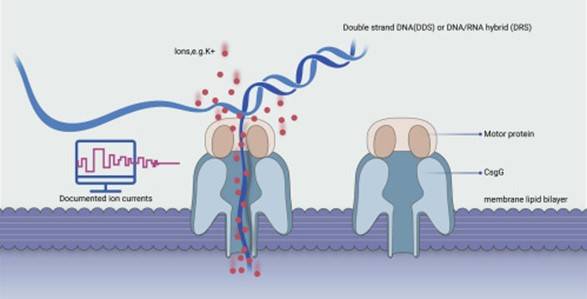 ONT direct DNA sequencing (Shangqian Xie et a., 2021)
ONT direct DNA sequencing (Shangqian Xie et a., 2021)
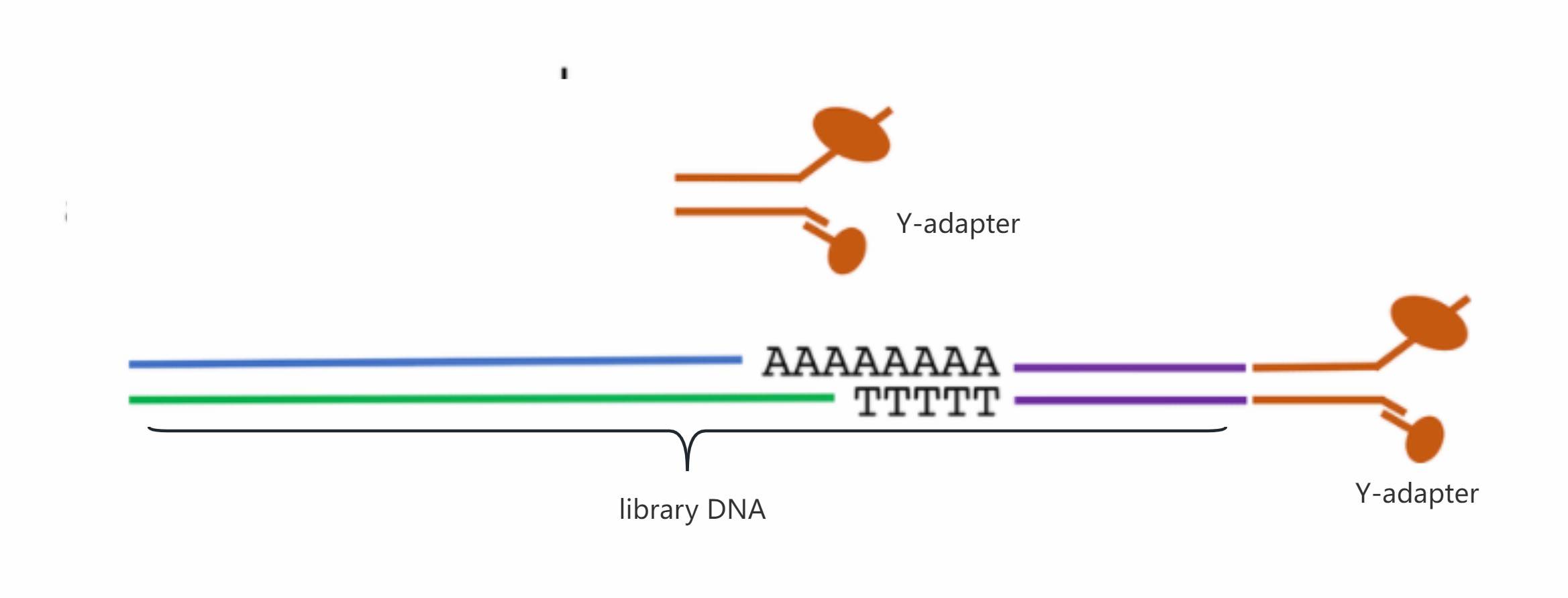
Since nucleic acid molecules display a high degree of randomness while undergoing directionally controlled current flow in their untreated state, this is not conducive to sequencing. Therefore, like other high-throughput sequencing methods, nanopore sequencing also requires library construction.
Two strands of the library adapter are separately connected to the motor protein and a Y-adapter. The Y-adapter interacts with the connector arm on the membrane, assisting in library positioning on the nanopore. The motor protein on the adapter, in direct interaction with the nanopore protein, aids library positioning during sequencing. It facilitates unwinding of the nucleic acid and regulates the rate of translocation through the pore.
Summary
Evidently, the initial signal collected by nanopores is an electrical one. Since the signal relates to the molecular size in the channel pore, various modification information on nucleic acid remains preserved within the electrical signal. Ultimately, the sequencer stores the electrical signal in the form of 'fast5' files. Following the base identification process, 'fast5' files convert to 'fastq' files, which contain the ATCG base sequence.
Nanopore bases are read in units of five bases per electrical signal, which differs from synthesis-while-sequencing methods. Hence, strictly speaking, Q-values, used for second-generation sequencing quality assessment, are inapplicable to nanopore sequencing. The Q-value definition is the probability of an error occurring for each base measured. Therefore, evaluating nanopore sequencing using a single base quality value is inappropriate. Nanopore sequencing employs its own unique set of quality control standards, referred to as consensus accuracy.
It's worth noting that the accuracy of nanopores is continually improving. As of 2023, the newly developed Q20 reagent ensures that the median sequencing accuracy surpasses 99%. Similarly, high-throughput sequencing is not an absolute standard. It ultimately determines the base at a given locus by assessing the depth of sequencing at that locus.
For a more in-depth understanding of Nanopore Sequencing, consider referring to the following articles: "Why Choose Nanopore Sequencing", "Nanopore Sequencing for Structural Variation Detection, HLA Typing, and STR Analysis", "Application of nanopore sequencing technology", "Nanopore Sequencing: Principles, Platforms and Advantages", and "Full-length Transcript Sequencing: A Comparison Between PacBio Iso-Seq and Nanopore Direct RNA-Seq".


