
 Sample Submission Guidelines
Sample Submission Guidelines
The Complete Overview of Long-Read Sequencing in 2024
Background of Long-Read Sequencing
Genetic sequencing technology, also known as DNA sequencing, is a methodology dedicated to the assessment of the base sequence arrangement within the targeted DNA fragments. Since sanger sequencing, significant developments have been made in next-generation sequencing technologies, providing higher sequencing efficiency as well as more accurate data outputs. According to the read length of the sequenced fragments , sequencing technologies can be categorized into short-read sequencing and long-read sequencing. Compared to short-read sequencing, long-read sequencing can directly generate sequences > 10 kb from native DNA, and it can reliably resolve repeat sequences and large genomic rearrangements to enable more precise and complete detection of nucleic acid molecules, identifying structural variants and more transcripts in the genome. Now, long-read sequencing approaches are represented by Pacific Biosciences and Oxford Nanopore technologies,and due to its high throughput, long reads, and the ability to directly detect base methylation modifications, it is increasingly being applied in the fields of genome assembly, epigenetic markers, transcriptomics, and metagenomics.
Overview of long-read sequencing
What is the long-read sequencing methods?
Long-read sequencing(LRS), also known as third-generation sequencing, does not require DNA fragmentation for sequencing, thus spanning entire repetitive sequences and achieving continuous and complete assembly. With the improvement of sequencing throughput and accuracy, LRS technology can determine continuous sequences of tens of thousands to several megabases, and the technological maturity is steadily increasing.
Service you may interested in
Learn more
The main long-read sequencing methods currently are:
Nanopore Sequencing: Pioneered by Oxford Nanopore Technologies (ONT), nanopore sequencing involves passing single-stranded DNA molecules through a protein nanopore embedded in a synthetic membrane. As the DNA traverses the nanopore, it modulates the ionic current, allowing for real-time detection of nucleotide sequences. Nanopore sequencing offers portability, rapid turnaround times, and the ability to generate ultra-long reads, making it suitable for a wide range of applications, including clinical diagnostics, infectious disease surveillance, and metagenomics studies.
Service you may interested in
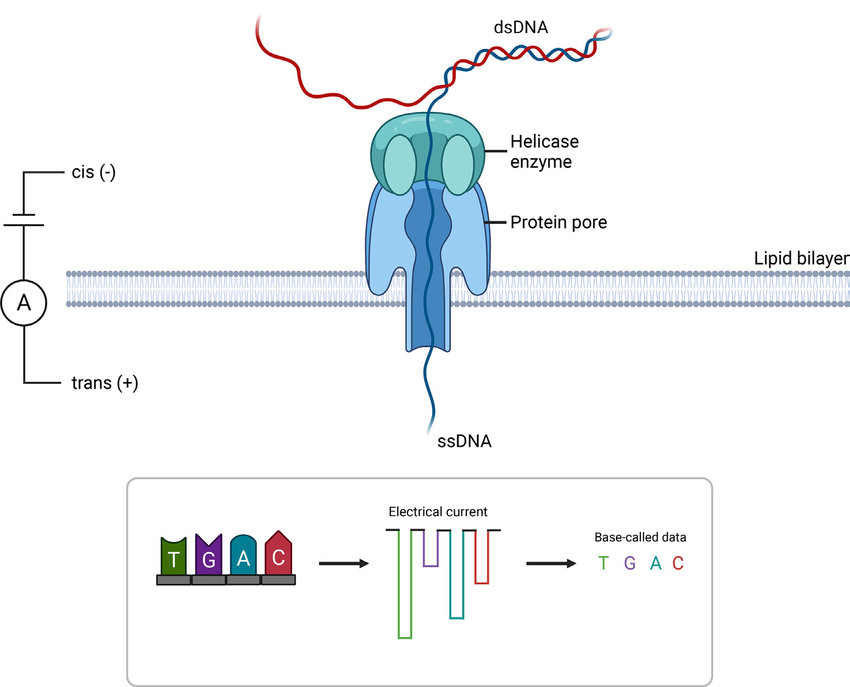 A schematic diagram of the mechanism of Oxford Nanopore Technologies (ONT) sequencing(Figure created using BioRender.com)
A schematic diagram of the mechanism of Oxford Nanopore Technologies (ONT) sequencing(Figure created using BioRender.com)
Single-Molecule Real-Time (SMRT) Sequencing: Developed by Pacific Biosciences (PacBio), SMRT sequencing utilizes a unique sequencing-by-synthesis approach. It involves immobilizing single DNA polymerase molecules on a solid surface within zero-mode waveguide (ZMW) nanostructures. Each ZMW contains a tiny well where sequencing occurs. During sequencing, fluorescently labeled nucleotides are added to the polymerase-bound DNA template, and the emitted light signals are detected in real-time. This method produces long reads with high accuracy and is particularly useful for resolving complex genomic regions, such as repetitive sequences and structural variations.
Service you may interested in
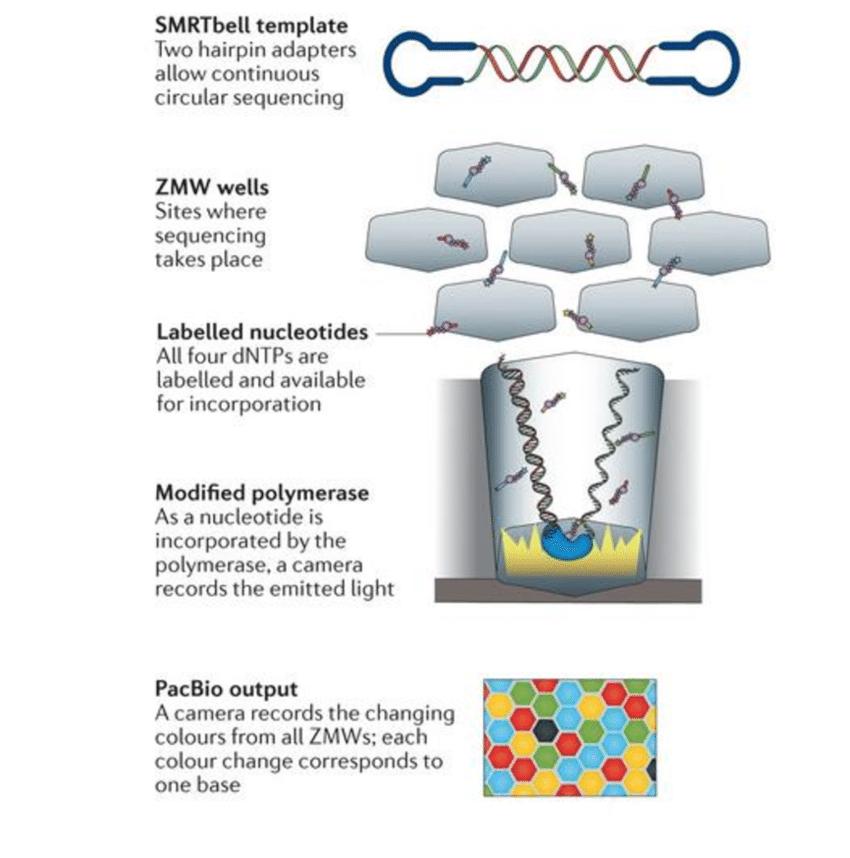 Principle of Single-molecule real-time (SMRT) sequencing from PacBio (Goodwin, McPherson and McCombie, 2016)
Principle of Single-molecule real-time (SMRT) sequencing from PacBio (Goodwin, McPherson and McCombie, 2016)
Long-read sequencing VS short read sequencing
How does they work?
Long-read sequencing and short-read sequencing have different working principles based on the length of DNA fragments.
Long-read sequencing works in the following steps, first the DNA fragments are broken down into larger fragments ranging from thousands to tens of thousands of base pairs in length, and sequencing adapters are attached to the ends of the DNA fragments. The prepared DNA library is loaded onto the long-read sequencing platform. In SMRT sequencing, DNA polymerase molecules are immobilized on a solid surface within a zero-mode waveguide (ZMW) nanostructure, allowing individual DNA molecules to bind to the DNA polymerase within the ZMW. Fluorescently labeled nucleotides are then added to the DNA template and the emitted light signal is detected in real time. The fluorescent signals are converted to nucleotide sequences by observing their timing and intensity. In Nanopore sequencing, DNA molecules are embedded in tiny protein nanopores in a synthetic membrane. As DNA passes through the nanopore, it causes characteristic disturbances in the ionic currents flowing through the pore. These disturbances are detected and recorded as electrical signals, which are then converted to nucleotide sequences using specialized algorithms. These sequences are then aligned to a reference genome or subjected to denovo assembly to identify genetic variants, structural rearrangements and other genomic features.
The short-read sequencing work step by step package is as follows, first the target DNA fragments are broken down into smaller fragments and then sequencing adapters are attached to the ends of the DNA fragments. The processed DNA fragments are attached to solid surfaces such as glass slides or flow cells through connectors. The DNA fragments are amplified into identical clusters by bridge amplification or cluster generation. Each cluster represents a DNA fragment from the original sample, and the DNA sequences in each cluster are then read simultaneously using a sequencing platform. Illumina sequencing is one of the most commonly used short-read sequencing platforms, which utilizes a reversible terminator approach. Fluorescently labeled nucleotides are added to clusters of DNA fragments. As each nucleotide is incorporated into the growing DNA strand, its fluorescent labeling is imaged and recorded, the fluorescent labeling is removed after recording, and the next nucleotide is added. Multiple cycles are performed to generate DNA sequence reads. The fluorescent signals or nucleotide sequences are then processed and converted to a digital format. The short sequence reads are then compared to a reference genome or reassembled.
What are the advantages and disadvantages of long-read sequencing and short read sequencing?
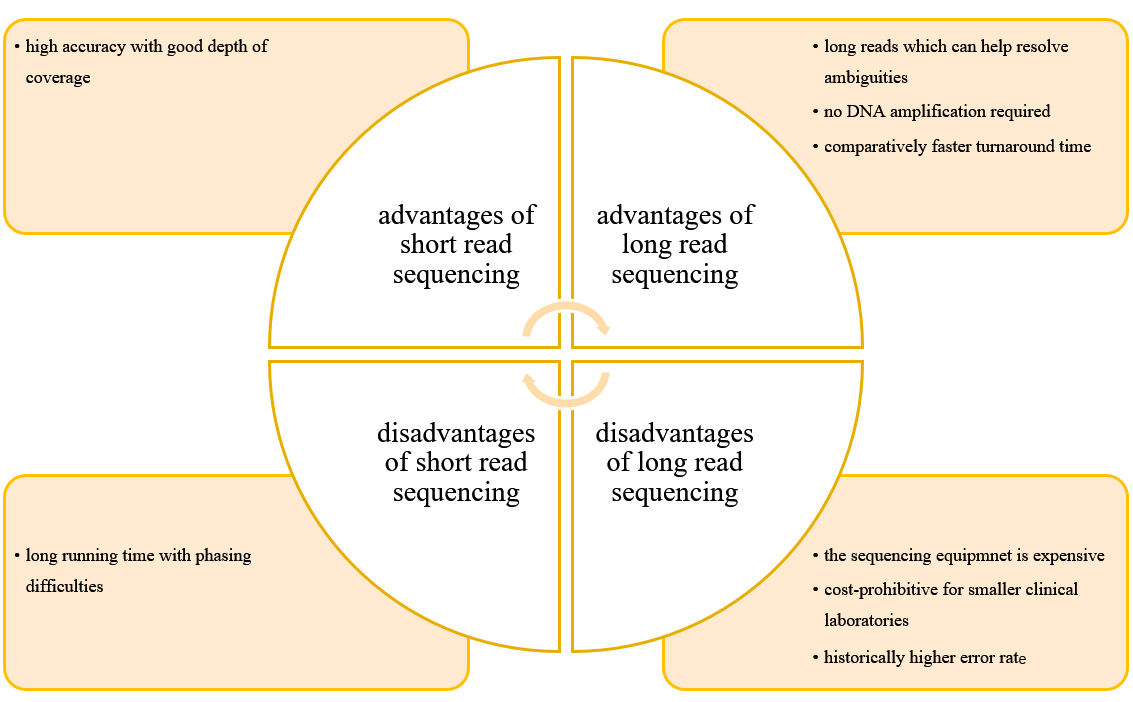
The advantage of CD Genomics' long-read sequencing
Long reads and high accuracy
The cd-genome's proprietary sequencing technology provides extremely high accuracy and resolution to accurately detect complex genomic variants.
Versatility and adaptability
The long-read sequencing platform of cd-genomic has a wide range of applications, suitable for various applications from basic research to clinical diagnosis. Such as epigenetic markers, transcriptomics, metagenomics, etc.
Streamlined workflow and scalability
The long-read sequencing workflow of cd-genomic is designed to improve efficiency and scalability, allowing real-time data collection and providing faster turnaround time.
The Workflow of CD Genomics Long-read Sequencing
Sample Preparation
- DNA extraction: Extract high-quality DNA samples from the target organism or tissue.
- Library preparation: Use cd-genomic's proprietary protocols to fragment DNA into larger fragments ranging in size from thousands to tens of thousands of base pairs in length, and selecting appropriate adapters.
Sequencing
- Loading: Load prepared sequencing libraries onto the cd-genomic long-read sequencing platform.
- Sequencing: Generated the long-read sequences in real time using cd-genomic's advanced sequencing technology.
Data Analysis
- Basic Analysis: Converts raw electrical or fluorescent signals generated during sequencing into nucleotide sequences.
- Read alignment: mapping of sequenced long nucleotide sequences to a reference genome or denovo assembly, identification of genetic variants and structural rearrangements.
- Variant analysis: detects and analyzes genetic variants, including single nucleotide polymorphisms (SNPs), insertions, deletions, and structural variants.
- Annotation: annotation of detected variants.
Conclusion
Long-read sequencing helps to draw genome and transcriptome maps, enabling DNA detection, detection of large structural variations, and methylation detection, playing an indispensable role in genomic research. The use of multiple sequencing platforms for comprehensive analysis of targets is currently the main sequencing method used and has achieved good results. However, improving the accuracy of long sequencing is still our focus. With the continuous improvement of the accuracy of long-read sequencing technology, its role in scientific research will become increasingly important.
With advanced long-read sequencing technology and professional services, CD Genomics is dedicated to supporting genomics research. Embrace the future of genomics with CD Genomics and embark on a journey of discovery and innovation.
Reference:
- Hu, T., N. Chitnis, D. Monos and A. Dinh (2021). "Next-generation sequencing technologies: An overview." Hum Immunol 82(11): 801-811.


