Since the introduction of NGS, genome sequencing and resequencing have become the standard for sequencing crops and livestock. However, NGS has important limitations, such as inherent bias and unclear alignment of repetitive elements, which leads to a high degree of fragmentation in draft genome assemblies and complicates the study of hidden insertion deletions and structural variants. The advent of long-read sequencing, including Pacific Biosciences (PacBio) single-molecule real-time sequencing and Oxford Nanopore Technologies (ONT) sequencing, has enabled the generation of long read lengths and allowed for the generation of more accurate and contiguous genome assemblies. However, analyzing the large amount of data generated by long-read sequencing technologies is a complex multi-step process that is computationally intensive and often requires bioinformatics expertise.
Fig. 1. Mapping of HiFi reads identified structural variants in Arabidopsis mt genomes. (Zou et al., 2022)
Our agricultural long-read sequencing data analysis service
CD Genomics is a leading company in the field of agricultural genomics research, providing comprehensive agricultural long-read sequencing data analysis services. Our long-read sequencing data analysis services include multiple aspects of data analysis, such as whole genome sequencing data, transcriptome sequencing data, epigenomics data, metagenomics data, and targeted sequencing data. Based on cutting-edge long-read sequencing and bioinformatics analysis pipelines, we ensure the depth and accuracy of agricultural genome analysis.
While a variety of tools are available for mining genomic and variant data, handling the ever-growing amount of genomic data and selecting the appropriate analyses is also a major challenge for crop genomics researchers. Our extensive expertise in bioinformatics analysis ensures that state-of-the-art computational tools and processes are employed for your project and valuable insights are extracted from long-read sequencing data. Our long-read sequencing data analysis services provide the following information, including but not limited to:
Gene/gene subtype expression analysis. We utilize sophisticated algorithms and tools to accurately quantify gene and subtype expression levels. By analyzing long-read sequencing data, we help you identify differentially expressed genes and isoforms under different agricultural conditions, thereby revealing key biological processes and regulatory mechanisms.
Structural variation and genome assembly. Our advanced assembly algorithms optimized for long-read data enable the reconstruction of high-quality genomes and facilitate the identification of structural variants. Fully assembled and well-annotated genomes help breeders identify genes associated with agronomic traits, determine their location and function, and develop genome-wide molecular markers.
Epigenetic modifications and phenotypic characterization. We provide comprehensive long-read sequencing data analysis to reveal DNA methylation patterns, assess chromatin accessibility, and determine nucleosome localization. We aim to help our clients gain a deeper understanding of gene regulation and the impact of epigenetic modifications on agricultural traits.
Comparative genomics and evolutionary studies. Our long-read sequencing data analysis enables researchers to explore evolutionary relationships, identify conserved regions, and discover genetic innovations that contribute to the adaptation and domestication of agricultural species.
Our services can be applied to the following research areas
Genomic breeding analysis. Our agricultural long-read sequencing data analysis services identify genetic variation associated with desired traits, ensuring more precise and efficient breeding strategies.
Genetic engineering validation and evaluation. Our agricultural long-read sequencing data analysis provides high-quality reference genomes that enable accurate characterization and validation of genetic modifications.
Pest and disease research. Our agricultural long-read sequencing data analysis services help you study the genomes of pests and pathogens in-depth, contributing to the development of targeted pest management and disease control strategies to safeguard crop and livestock health.
Our advantages and features
Expertise. Our skilled team of experts and advanced bioinformatics pipeline ensure reliable and reproducible results.
Customized solutions for specific research goals. We work closely with researchers to customize our analytical processes and methods to address their specific research questions.
State-of-the-art bioinformatics pipeline. Our pipeline employs state-of-the-art algorithms and tools that have been rigorously tested and optimized to handle the complexity of agricultural genomes.
CD Genomics provides comprehensive agricultural long-read sequencing data analysis services to accelerate crop improvement and promote sustainable agricultural practices. If you are interested, please feel free to contact us.
Reference
Zou, Yi, et al. "Long‐read sequencing characterizes mitochondrial and plastid genome variants in Arabidopsis msh1 mutants." The Plant Journal. 112.3 (2022): 738-755.
For research purposes only,
not intended for clinical diagnosis, treatment, or individual health assessments.
Send a Message
For any general inquiries, please fill out the form below.
We provide the best service according to your needs Contact Us
PDF Download
×
OUR MISSION
CD Genomics is propelling the future of agriculture by employing cutting-edge sequencing and genotyping technologies to predict and enhance multiple complex polygenic traits within breeding populations.

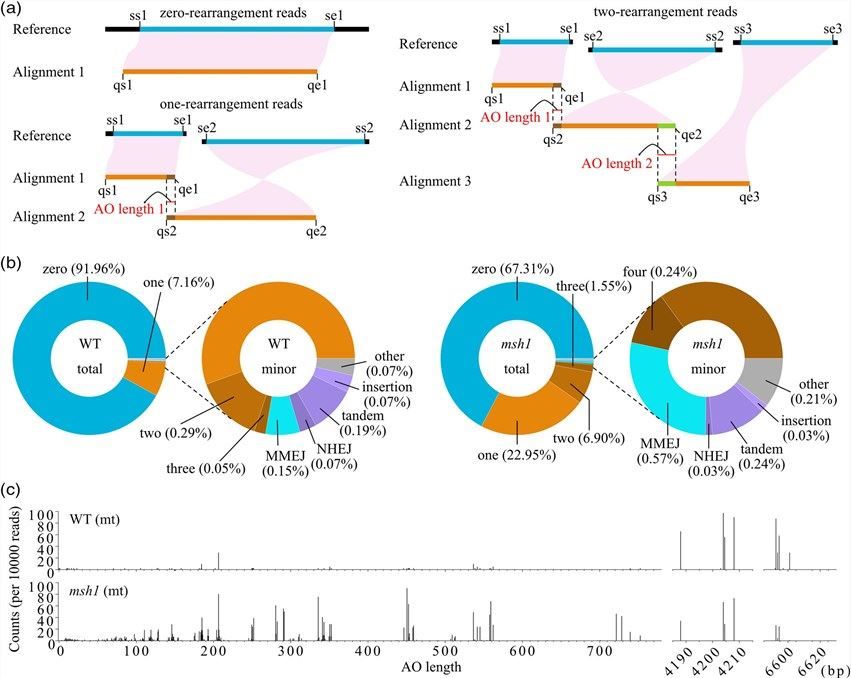 Fig. 1. Mapping of HiFi reads identified structural variants in Arabidopsis mt genomes. (Zou et al., 2022)
Fig. 1. Mapping of HiFi reads identified structural variants in Arabidopsis mt genomes. (Zou et al., 2022)


