During the long process of evolution, each individual has developed unique genetic traits due to a variety of factors such as geography and environment. However, the genome of a single individual can no longer encompass all the genetic information of an entire species. As the cost of genome sequencing decreases, pan-genome research has risen rapidly in recent years, offering new possibilities to explore the genetic diversity and evolution of species.
Pan-genome research is a popular research direction. By sequencing (NGS and long-read sequencing) and assembling the genomes of different species and integrating the annotated gene sequences, we are able to gain comprehensive access to the genetic information of a species, and then analyze in-depth the genetic variation among individuals.
Our pan-genome service utilizes high-throughput sequencing and bioinformatics analysis to sequence and pan-assemble materials of different subspecies or individuals, thereby constructing a pan-genome map that enriches the genetic information of the species. The service can not only improve the gene set of the species, but also obtain the DNA sequence and functional gene information of specific populations or even individuals, providing a solid foundation for phylogenetic analysis and functional biology research.
In the field of plants, higher plants exhibit extremely high intraspecific genetic diversity to adapt to different growth environments. By constructing species pan-genomes, we can reconstruct the phylogenetic relationships between cultivated and wild varieties and study population-level recombination and cascade effects. Combined with the distribution of variants in each species in the pangenome, the expression of variants is detected using transcriptomic analysis, and trait-related variants are identified in combination with phenotypic information. With the variant information obtained through pan-genomic research, GWAS analysis is performed based on the structural variants to identify the loci associated with agronomic traits and provide genetic resource information for molecular breeding.
Animal pan-genome research
Compared with plants, the scope of animal pan-genomic research is more limited, mainly focusing on humans and domesticated animals. By constructing large-scale population genomes and focusing on species with certain common characteristics, it is possible to explore in depth the characteristic differences in the genomic structure of species, their formation history, convergent evolution, group characteristics, genome evolution and potential functions. By constructing pan-genomes of different strains, subspecies and variants, we can establish a comparison between core and non-core genomes, and compare the genotypic differences between groups in different geographical regions, thus revealing the environmental adaptations of species.
Application
Selecting different subspecies materials for pan-genome sequencing aids in studying essential biological questions such as the origin and evolution of species.
Choosing diverse germplasm resources, including wild and cultivated varieties with different characteristics, for pan-genome sequencing allows the discovery of gene resources related to important traits, guiding scientific breeding.
Pan-genome sequencing of germplasm resources from different ecological and geographical types enables the study of species' adaptive evolution, invasive characteristics of foreign species, and other hot scientific issues, providing new research methods for disciplines like molecular ecology.
The short-read sequencing technique, while highly accurate, is limited by its read length of only about 100-200 nucleotides. Although it can reveal smaller variants like SNPs and inDels through contig-level assembly, it falls short in capturing larger variant types. Early pan-genome approaches often relied on mapping contigs to a reference genome, producing gene-centric pangenomes that may overlook complex structural variants crucial for gene regulation and genome evolution.
To overcome these limitations, we advocate for long-read sequencing, particularly leveraging PacBio and Nanopore platforms. By integrating next-generation and long-read technologies, this sequencing strategy constructs higher-quality genomes, enabling unbiased comparisons and revealing positional relationships and differences between them.
PacBio SMRT Sequenicng & Nanopore Sequenicng
PacBio Single Molecule, Real-Time (SMRT) sequencing and Nanopore sequencing offer distinct advantages in genome assembly continuity and structural variation detection. These long-read technologies cover the entire genome without bias, providing accurate detection of various variants, including SNPs, indels, and structural variations. Their application holds significant promise in analyzing the genetic mechanisms underlying important crop traits. This, in turn, facilitates the design of genome-assisted breeding strategies, contributing substantially to the genetic improvement of crops.
Workflow
CD Genomics pan-genome service
Case Study
Construction of the Soybean Pan-Genome Atlas
Soybeans are a crucial source of edible oil and plant protein worldwide and a potential raw material for biofuels, holding a significant position in global agricultural trade. In comparison to traditional resequencing studies, pan-genome sequencing of multiple individuals provides a more comprehensive detection of genetic variations within the species. This approach offers a fresh perspective for in-depth understanding of the genetic characteristics of soybeans.
Genetic Variations from 29 Soybean Genomes and 2,898 Resequenced Accessions. (Liu et al., 2020)
Genome Size: The wild soybean genomes range from 889.33Mb to 1118.34Mb, representing 93.6% to 117.7% of the cultivated soybean genome. This difference is attributed, to some extent, to variations in repetitive sequence content.
Genome Assembly and Annotation: The contig N50 of the assembled wild soybean genomes ranges from approximately 7.7 to 26.6 kb, and the scaffold N50 ranges from approximately 16.3 to 62.7 kb. On average, each genome is annotated with 55,570 genes, of which 85-90% are full-length genes.
Pan-Genome Construction: Comparative analysis of seven independently assembled wild soybean genomes reveals a total of 59,080 gene families (pan-genome). Approximately 48.6% of these gene families constitute a shared core-genome across all seven wild soybeans, while the remaining 51.4% are found exclusively in individual samples.
Variation Detection and Annotation: Using the cultivated soybean genome as a reference, SNP identification in the seven wild soybeans ranges from 3.6 to 4.7 million, with 0.12 to 0.15 million located in coding regions. Indel detection ranges from 0.50 to 0.77 million, resulting in 2989 to 4181 frameshift mutations. A significant portion of variation sites (44-53%) represents novel sites not identified by resequencing methods.
Evolutionary Analysis: Divergence time analysis indicates that the wild soybean and cultivated soybean ancestors diverged approximately 800,000 years ago. Positive selection analysis on cultivated and wild soybeans reveals that cultivated soybeans exhibit a higher proportion of genes under selection related to drought resistance, possibly due to artificial selection. In contrast, selected genes in wild soybeans are diverse, with different types of genes under positive selection in wild soybeans from various geographical regions.
Agronomic Trait Gene Mapping: Numerous genes and variations associated with crucial agronomic traits such as stress resistance, disease resistance, flowering period, oil yield, and plant height are identified. For instance, a segment of 8kb on chromosome 14 is associated with stress resistance and plant development in wild soybeans. The difference in flowering time between wild and cultivated soybeans is linked to SNP and InDel variations in flowering time regulatory genes.
Reference
Liu, Yucheng et al. "Pan-Genome of Wild and Cultivated Soybeans." Cell vol. 182,1 (2020): 162-176.e13.
For research purposes only,
not intended for clinical diagnosis, treatment, or individual health assessments.
For any general inquiries, please fill out the form below.
We provide the best service according to your needs Contact Us
PDF Download
×
OUR MISSION
CD Genomics is propelling the future of agriculture by employing cutting-edge sequencing and genotyping technologies to predict and enhance multiple complex polygenic traits within breeding populations.

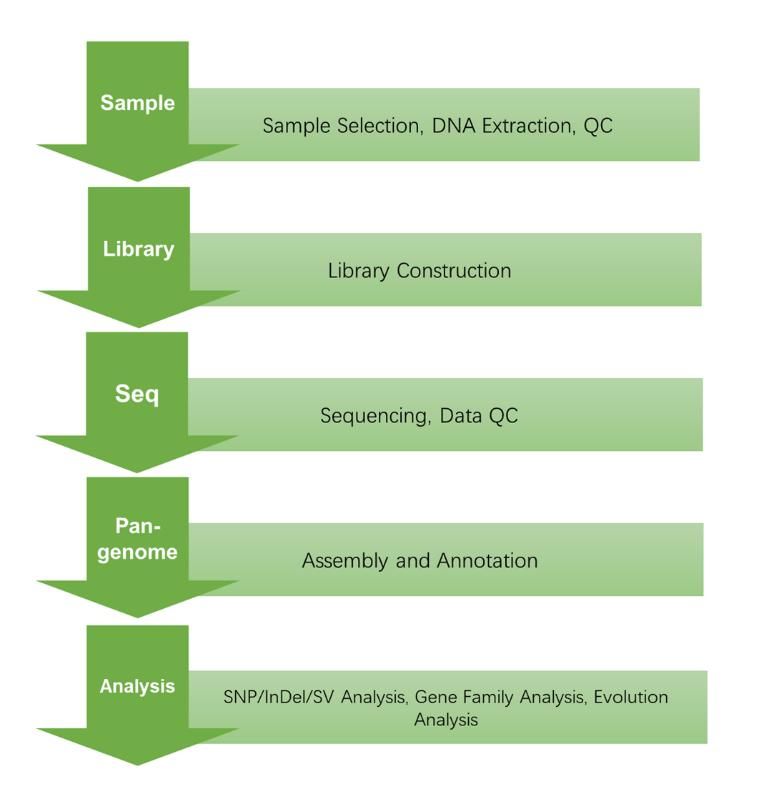 CD Genomics pan-genome service
CD Genomics pan-genome service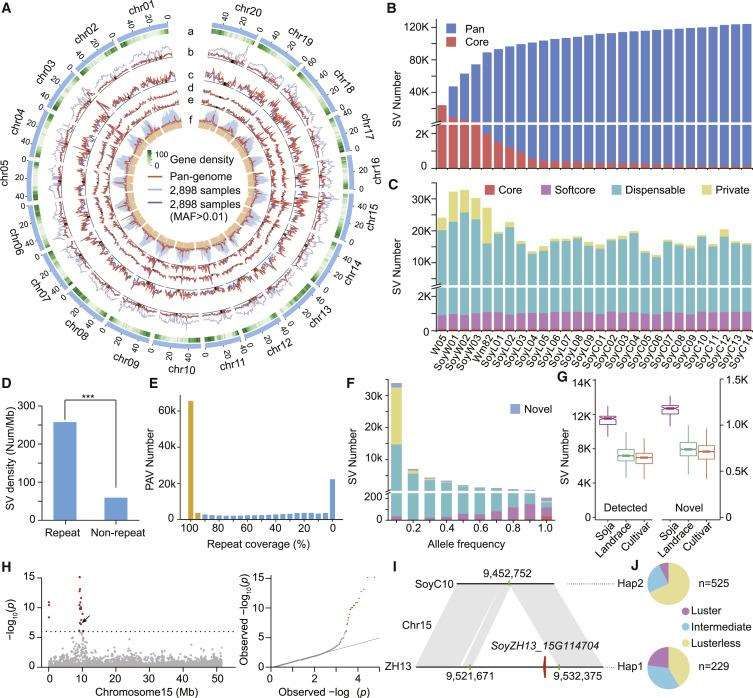 Genetic Variations from 29 Soybean Genomes and 2,898 Resequenced Accessions. (Liu et al., 2020)
Genetic Variations from 29 Soybean Genomes and 2,898 Resequenced Accessions. (Liu et al., 2020)



