Bioinformatics in Data Mining and Data Landscaping
Introduction of Data Mining & Data Landscaping
In recent years, research on genomics, transcriptomics, proteomics, microbiology, metabolomics and various other fields of biological research has generated more and more biological data. So now a large amount of data available in the public domain can be effectively used for mining specific biological problems of interest. Drawing conclusions from these data requires complex calculations and analysis to interpret the data. One of the most active areas of inferring the structure and principles of biological data sets is the use of data mining to solve biological problems. Data Mining (DM) is the process of automatic discovery of novel and understandable models and patterns from large amounts of data. And data mining is sometimes called Knowledge Discovery in Database (KDD).
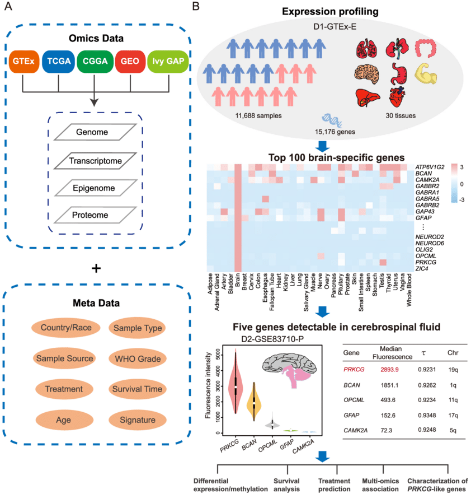 Fig 1. Datasets and bioinformatic analysis workflow. (Lin L. et al. 2020)
Fig 1. Datasets and bioinformatic analysis workflow. (Lin L. et al. 2020)
Advantages of Data Mining & Data Landscaping
- Use the large amount of available data in public domain databases to effectively mine specific biological problems of interest.
- Greatly reduce the time and cost associated with wet laboratory experiments and data generation.
- In many cases, public data sets provide a good resource for verifying experimental research findings.
- Through the existing data in the public database, new and feasible research ideas are found.
Tasks Performed by Data Mining
As mentioned above, data mining is the process of automatically generating information from existing data. The main goals of data mining are "prediction" and "description". The main tasks that can be performed with data mining are as follows:
- Classification: Classification is the learning of the function of mapping/reading (classifying) input data items into one of several predefined categories (existing data).
- Estimate: Given some input data, get the value of some unknown continuous variables.
- Prediction: Same as classification and estimation, but the difference is that the recording method is classified according to future behaviors or evaluation values.
- Association rules: Determine which data is combined together, also known as dependency modeling.
- Clustering: Divide the population into multiple subgroups or clusters.
- Description and visualization: Describe data or use visualization techniques to represent data.
CD Genomics Technical Process
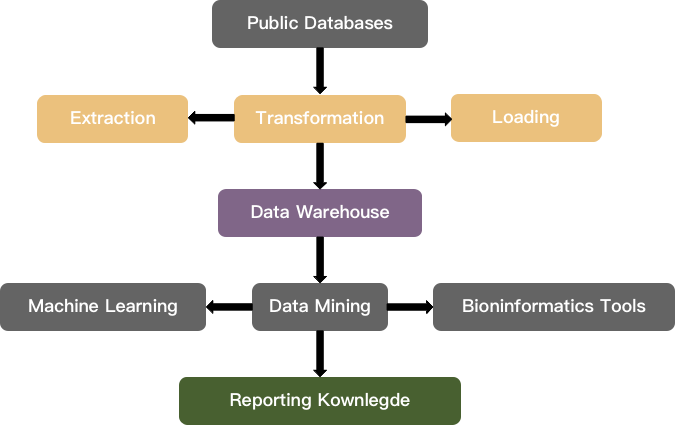 Fig 2. Process of knowledge discovery through data mining.
Fig 2. Process of knowledge discovery through data mining.
CD Genomics' Data-Mining Serivce
CD Genomics' new data mining service utilizes cutting-edge methods in machine learning, statistics and database systems. This service supports new discoveries that provide new insights by analyzing patterns in big data sets. Once the appropriate data set is determined, CD Genomics can adopt reliable quality control procedures to provide the best starting point for downstream analysis and research. We can use standard or customized workflows to perform data mining. Our team also has experience in meta-analysis, which combines data and results from multiple studies to improve overall statistical capabilities.
Applications
In the field of biomedical research, data mining technology helps to propose active research in specific areas of the biomedical industry. It enables researchers to better understand biological mechanisms and discover new therapies in the field of medical and drug research. For example, if you have data from patient cohorts, or any other omics program, our service team will provide enhanced support with optimal data analysis by using our latest data mining technology.
CD Genomics uses a variety of algorithms to achieve advanced data mining and data landscaping with its rich data mining experience, and uses the most optimal combination of algorithms specific to your data. Our goal is to build a powerful classifier to divide the data into two or more classes or groups based on relevant data. In addition, we can mine different and multiple omics data at the same time. Integration with phenotype and/or clinical data is also possible. For data mining and data landscaping, if you have any questions, please feel free to contact us for more details.
References
- Lin L. et al. Computational identification and characterization of glioma candidate biomarkers through multi-omics integrative profiling[J]. Biology Direct, 2020, June,15(1). DOI: 10.1186/s13062-020-00264-5.
- Khalid R . Application Of Data Mining In Bioinformatics[J]. Indian Journal of Computer Science and Engineering, 2010, 1(2).
- Momeni Z, et al. A Survey on Single and Multi Omics Data Mining Methods in Cancer Data Classification[J]. Journal of Biomedical Informatics, 2020, 107:103466.
* For research use only. Not for use in clinical diagnosis or treatment of humans or animals.
Online Inquiry
Please submit a detailed description of your project. Our industry-leading scientists will review the information provided as soon as possible. You can also send emails directly to for inquiries.