MeRIP-qPCR for Single-Gene Validation: How to Test Whether a Compound Reduces m6A Enrichment
MeRIP-qPCR is often the most practical way to test whether a compound changes m6A enrichment at a predefined target when your goal is focused confirmation, not transcriptome-wide discovery. If you already have a candidate gene and a plausible region, this targeted approach can quickly indicate whether the treatment reduces relative m6A signal at that site. In this guide, you'll find a decision framework for MeRIP-qPCR single gene validation, a compact MeRIP-qPCR workflow overview, and a step-by-step example showing how to separate enrichment change from expression change-so the result you report is interpretable and defensible for m6A inhibition validation or other targeted m6A validation scenarios.
Key takeaways
- MeRIP-qPCR is a validation assay for predefined targets; it's not a discovery platform.
- Interpret immunoprecipitated (IP) signal in the context of input RNA to avoid confusing expression shifts with enrichment changes.
- Region choice matters more than the gene label; design primers to the most plausible enriched window and consider a same-transcript reference region.
- A credible "reduction in m6A enrichment" claim rests on matched treatments, input-normalized comparisons, and biological replication.
- Use MeRIP-qPCR for fast directionality; scale to broader profiling or orthogonal assays only when the targeted result justifies it.
Quick decision: is MeRIP-qPCR the right first-step?
If you're choosing a first assay for MeRIP-qPCR single gene validation, it helps to be explicit about what you need to decide.
Use MeRIP-qPCR first when:
- You already have a candidate transcript and a plausible region (or a strong literature-backed window) you can target with primers.
- Your primary question is directional: does treatment reduce relative m6A-IP capture at that region compared with matched controls?
- You can run matched input + IP for every sample and you have biological replicates.
Don't use MeRIP-qPCR as your first step when:
- You only have a gene name, but no region strategy (isoforms, 3' UTR choice, or prior peak evidence are unresolved).
- You need transcriptome-wide selectivity, pathway breadth, or a genome-scale view of off-target effects.
- You need base-resolution answers (which adenosine is modified, or what fraction is modified).
Escalate when:
- The baseline enrichment is near background, making small fold shifts unstable.
- The treatment changes input RNA abundance enough that enrichment vs expression is hard to disentangle.
- A single-gene result needs to become a mechanism or selectivity claim (move to broader profiling and/or orthogonal, site-directed methods).
When MeRIP-qPCR Is the Right Tool for the Question
This is a validation assay, not a discovery platform
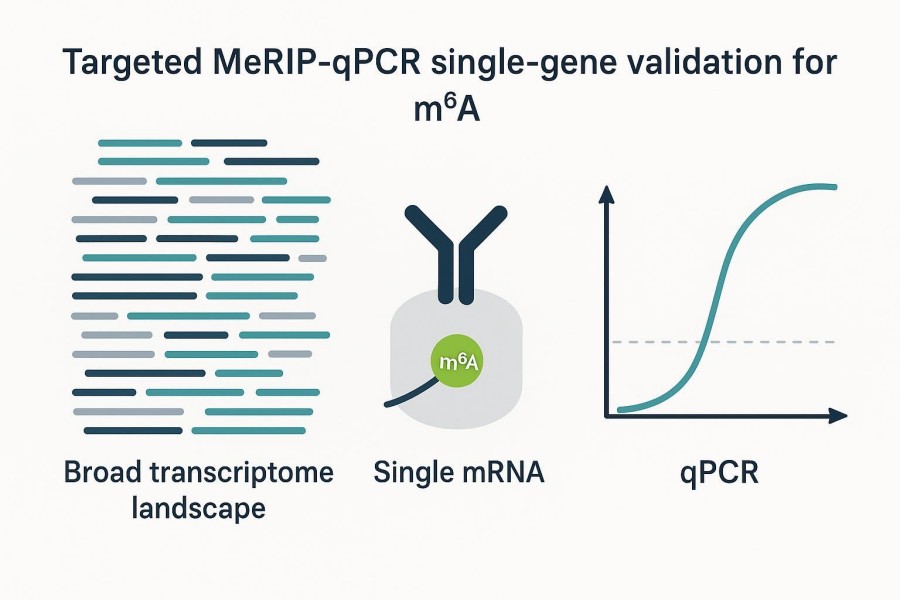
MeRIP-qPCR works best once your research team has a candidate gene and, ideally, a short transcript region that is likely m6A-modified (for example, near the stop codon or in the 3' UTR). Compared with sequencing-based assays, it yields focused evidence about a specific hypothesis-does the IP-enriched signal for this region change relative to input under treatment? Methods papers consistently show MeRIP-qPCR used to confirm sequencing-derived peaks or to check predefined regions rather than to perform de novo discovery. For instance, an integrated workflow describes using MeRIP-seq to find candidates and then applying qPCR to validate selected peaks, with normalization against input for interpretation, as detailed in a 2023 workflow paper in CSBJ by Shi and colleagues (see the discussion of validation steps in the integrated pipeline) in the article titled An experimental workflow for identifying RNA m6A alterations (Shi 2023).
What kind of treatment question this assay can answer well
If the primary question is whether a compound, perturbation, or condition reduces relative m6A enrichment at a known site, MeRIP-qPCR is a good fit. The assay compares IP capture for the target region across treatment and control groups while keeping track of input RNA as the context for expression. A positive result supports a directional shift in enrichment under the tested condition. It does not, by itself, prove a direct mechanism or transcriptome-wide selectivity; we address those boundaries below, with links to recent literature including McIntyre and co-authors' 2020 communication on detection limits in MeRIP/m6A-seq and the central role of replication and input-aware analysis in interpreting dynamic changes (McIntyre 2020).
When this assay is a better first step than transcriptome-wide profiling
When the team already has a sharp hypothesis-one gene, one plausible window-and needs an early read on direction before committing to broader assays, MeRIP-qPCR can be faster to execute and easier to interpret. Well-designed targeted checks can filter weak hypotheses and prioritize promising ones for expansion. If the first-directional result is consistent across biological replicates and reasonably sized in magnitude, then broader methods (for example, MeRIP-seq for transcriptome context or site-directed assays for base resolution) become easier to justify.
 MeRIP-qPCR is best positioned as a targeted validation assay when the research question is already defined.
MeRIP-qPCR is best positioned as a targeted validation assay when the research question is already defined.
What a Positive Result Actually Means - and What It Does Not
What a reduction in enrichment can support
A lower IP signal relative to input under treatment-quantified as a reduction in %Input or normalized fold-enrichment-supports the interpretation that relative m6A enrichment at the tested region is reduced in the treated condition compared with the matched control. This is the core readout most teams seek during compound evaluation.
Why this does not automatically prove direct mechanism
Enrichment differences alone cannot prove that the compound directly inhibits a writer complex component or demethylase, or that it is selective for this target over all others. Additional evidence is required to connect target engagement and specificity, such as dose-response consistency, orthogonal assays with site-level resolution, or transcriptome-wide profiling to assess breadth. Caution about over-interpretation is widely emphasized in recent evaluations of MeRIP-based methods; see the replication and interpretation guidance in McIntyre and colleagues' 2020 analysis of MeRIP/m6A-seq detection limits (McIntyre 2020).
Why input and expression context still matter
Changes in transcript abundance, RNA integrity, or amplicon placement can shift Ct values in ways that mimic enrichment changes. Interpreting IP in isolation is risky. Normalizing IP to input-either as %Input or through ΔCt/ΔΔCt logic with appropriate dilution corrections-helps maintain a distinction between "less RNA present overall" and "less of the RNA is captured by m6A-IP." This principle underpins many RNA IP/qPCR validations and is discussed in integrated m6A workflows such as the 2023 CSBJ paper (Shi 2023).
Start with the Target Region, Not Just the Target Gene
Why transcript region choice matters in m6A validation
m6A is not uniformly distributed along transcripts. It tends to concentrate near stop codons and in 3' UTRs for many poly(A) mRNAs, a pattern influenced by VIRMA/KIAA1429 as part of the writer complex. Region-aware design is, therefore, essential. Reviews and studies-such as Yue and co-authors' 2018 Molecular Cell report on VIRMA's role in 3'-region preference-provide a mechanistic rationale for prioritizing particular transcript windows when designing MeRIP-qPCR amplicons (see VIRMA-mediated 3' UTR preference in Yue 2018). Broader syntheses of writer complex components and regional bias are summarized in a 2021 Signal Transduction and Targeted Therapy review (Huang 2021).
What makes a region more suitable for MeRIP-qPCR
A suitable region typically shows one or more of the following: prior evidence of enrichment (from your own MeRIP-seq or the literature), DRACH-rich sequence context near a regulatory landmark (such as the stop codon), an expected enrichment window that fits amplicon design constraints, uniqueness across isoforms to avoid unintended cross-amplification, and a size compatible with robust qPCR performance. In practice, you'll balance biological plausibility (motif, location, prior peaks) with technical realities (primer specificity, GC content, and amplicon length).
Why one gene may still need more than one amplicon strategy
A "gene-level" question can still be region-specific in practice. If feasible, pair a candidate enriched amplicon with a same-transcript reference or low-enrichment amplicon. Comparing these regions under matched conditions can reveal whether the observed change is focused on the candidate window or instead reflects broader, non-specific effects. This intra-transcript comparison also guards against accidental isoform bias when multiple isoforms share primers or differ in 3' UTR composition.
The Experimental Design Should Separate m6A Change from Expression Change
Careful normalization and control structure help you interpret MeRIP-qPCR single gene validation results correctly and avoid conflating expression shifts with enrichment changes.
Why input RNA and IP signal must be interpreted together
IP Ct values without input context are difficult to trust. A widely used approach expresses IP capture as a fraction of input-%Input-or uses ΔCt/ΔΔCt logic. Both rely on analyzing IP and input together. Integrated method papers that combine discovery with validation reiterate this principle, either explicitly in qPCR steps or implicitly in input-aware modelling; see Shi and colleagues' 2023 workflow for m6A alteration identification as an example of validation thinking that keeps input in the loop (Shi 2023).
Why treatment-induced expression shifts can complicate interpretation
If treatment reduces transcript abundance, IP Ct values may rise simply because there is less RNA overall. Input-normalized enrichment measurements mitigate this, but interpretation should still consider whether input changed materially. McIntyre and co-authors highlighted how expression and enrichment can be intertwined and why replication and input-aware analysis are essential for credible differential claims (McIntyre 2020).
Why matched controls matter in compound-response studies
Vehicle vs untreated vs compound-treated groups, processed with matched handling, provide the structure needed to attribute changes to treatment rather than batch or handling differences. Negative controls for the IP (such as IgG or no-antibody) and negative or low-enrichment regions for specificity context further support interpretation. The logic of adding positive and negative regions in RNA IP/qPCR validations is also illustrated in recent STAR Protocols applications for viral RNA where MeRIP-RT-qPCR is used to confirm candidate sites by contrasting expected positive and negative regions; see the 2022 protocol by Li and colleagues for an example of how region-level controls are structured even outside human mRNA models (Li 2022).
| Readout | What it reflects | What it does not prove | Why it matters |
|---|---|---|---|
| IP Ct alone | Amount of target RNA captured in IP | Expression-normalized enrichment; site-level methylation | By itself, cannot distinguish abundance vs enrichment changes |
| %Input | Proportion of total target captured by IP | Base-resolution occupancy; direct mechanism | Normalizes IP to input; comparable across conditions |
| ΔΔCt (treated vs control) | Relative change in enrichment when normalized | Transcriptome-wide selectivity; writer/eraser specificity | Captures directional effect under treatment when normalized |
| IgG fold over background | Specific enrichment over non-specific binding | Site identity; absolute methylation fraction | Validates antibody-dependent specificity |
A simplified hypothetical data example: separating enrichment from expression
Suppose you test one transcript with two regions: Candidate (likely enriched) and Reference (low-enrichment). You measure IP and Input Ct values for Vehicle and Compound conditions (triplicates; shown here as means for brevity). Assume identical dilution corrections are applied to IP and Input where needed. Use these steps:
- ΔCt = Ct(IP) - Ct(Input)
- %Input ≈ 2^(-ΔCt) × 100% (include dilution factors if applicable)
- ΔΔCt_normalized = ΔCt(Treated) - ΔCt(Control)
- Fold-change in enrichment (Treated vs Control) ≈ 2^(-ΔΔCt_normalized)
| Region | Condition | Ct(IP) | Ct(Input) | ΔCt | %Input | ΔΔCt vs Vehicle | Enrichment fold-change |
|---|---|---|---|---|---|---|---|
| Candidate | Vehicle | 28.2 | 24.2 | 4.0 | 6.25% | - | - |
| Candidate | Compound | 30.0 | 24.1 | 5.9 | 1.78% | +1.9 | ~0.27× |
| Reference | Vehicle | 34.5 | 24.3 | 10.2 | 0.08% | - | - |
| Reference | Compound | 34.7 | 24.2 | 10.5 | 0.06% | +0.3 | ~0.81× |
Interpretation: The Candidate region shows a ~3.7-fold reduction in normalized enrichment (0.27×) with nearly unchanged input Cts, supporting reduced relative m6A enrichment at that region under compound treatment. The Reference region remains near background with a modest shift, suggesting the effect is focused rather than broadly non-specific. In practice, evaluate replicate variability, include background controls (e.g., IgG), and perform appropriate statistics. Normalization logic similar to the above appears across RIP/MeRIP validation practices and is aligned with input-aware comparisons discussed in recent method papers such as the CSBJ workflow and RIP-qPCR normalization discussions in NAR Cancer 2023 by Hodara and colleagues (see the normalization and comparison logic in Hodara 2023).
Controls That Make Single-Gene Validation More Trustworthy
Why input control is essential
Input RNA anchors your interpretation. Without it, IP changes cannot be distinguished from expression noise, RNA quality shifts, or sample-to-sample loading differences. Reporting %Input or an equivalent input-aware metric makes your result defensible to reviewers and collaborators.
Why matched treatment controls matter more than many readers expect
Untreated baseline and vehicle controls help isolate compound-associated effects from handling or solvent artifacts. Using matched processing (fragmentation, antibody lot, wash stringency) across conditions reduces batch-driven differences that can overshadow small but real enrichment shifts.
When a negative-region or low-enrichment comparator is useful
Including a same-transcript reference region (or a comparable negative region) helps demonstrate that a treatment-associated shift is focused on the candidate window. If both candidate and reference regions change similarly, suspect a non-specific effect or an upstream factor like expression or RNA integrity.
Why technical neatness does not replace biological replication
Clean qPCR curves are reassuring but cannot substitute for biological replicates. Reproducibility across independent samples guards against false positives and batch idiosyncrasies. The case for adequate replication when assessing dynamic changes in methylation-associated signals has been stressed in comparative analyses of MeRIP methods (see replication critiques in McIntyre 2020).
Replication and reporting are easier to defend when you match them to your decision goal. For a first directional check (go/no-go), biological triplicates are often treated as a practical minimum in lab workflows, but if you want to support smaller effect sizes, compare multiple targets, or make more quantitative claims, you typically need more biological replicates and stronger batch control. In practice, randomize processing order across groups, record batch variables (antibody lot, fragmentation run, qPCR plate), and present results in a way that shows variability-many reviewers prefer dot plots (each biological replicate) with a mean and confidence interval (or similar uncertainty), alongside the corresponding input behavior.
 Single-gene m6A validation depends on matched treatment structure, input context, and region-aware assay design.
Single-gene m6A validation depends on matched treatment structure, input context, and region-aware assay design.
What Usually Makes a MeRIP-qPCR Result Hard to Trust
Weak enrichment can create unstable interpretation
If baseline IP capture for the candidate region is near background, small fold changes are statistically and practically fragile. Consider revisiting region choice or incorporating additional replicates. Reporting IgG/background-normalized values alongside %Input can help readers gauge specificity.
Primer design can look like biology if the region is poorly chosen
Amplicons that straddle isoform junctions, overlap repetitive sequences, or capture heterogeneous transcript features can yield Ct shifts that track design artifacts rather than biology. Primer specificity and isoform mapping should appear in your deliverables to reduce this risk.
Expression change can be misread as methylation change
When treatment alters transcript abundance, IP-only comparisons become misleading. Input-aware normalization and transparent reporting of input shifts keep the biology and the measurement aligned.
Small fold shifts may not support strong claims
A 10-20% change, even if statistically significant, may not justify a confident mechanistic claim without additional context (dose-response, time course, broader profiling, or orthogonal validation). Several recent evaluations of MeRIP/m6A methods argue for both replication and effect-size awareness to avoid overstatement (see commentary and power considerations in McIntyre 2020).
A Practical Validation Path Before Scaling Up
Use MeRIP-qPCR to test the first directional hypothesis
Start with a strong candidate region and ask a narrow question: under your treatment, does normalized IP capture decrease at that site compared with matched controls? If yes, and replicates are concordant, you have directional evidence to motivate the next step.
Decide early what result would justify expansion
Before the experiment, define what magnitude and consistency of change would warrant broader investment. For example, you might set a threshold for fold-reduction and replication consistency that triggers transcriptome-wide profiling or site-level validation.
When one validated target is enough - and when it is not
In some projects, a single, well-supported instance of reduced enrichment at a mechanistically central transcript can meet the immediate decision need. In others-especially when mechanism, selectivity, or pathway breadth matters-you'll need more targets or broader coverage.
How this assay fits into a staged m6A study design
Think of MeRIP-qPCR as an early checkpoint. It can quickly filter hypotheses, allowing you to escalate to MeRIP-seq for transcriptome context or site-focused assays for mechanism once the signal justifies it. Reviews and workflows published since 2020 regularly combine targeted validation with follow-up profiling to move from a single region to system-level insight; see, for instance, the combined discovery/validation strategies summarized in the 2023 workflow by Shi and co-authors (Shi 2023).
 MeRIP-qPCR often works best as an early validation step in a staged m6A study strategy.
MeRIP-qPCR often works best as an early validation step in a staged m6A study strategy.
What Good Deliverables Should Look Like in a Targeted m6A Validation Project
Technical outputs that support confidence
Expect raw Ct tables for IP, input, and, if included, IgG controls for each region and replicate; explicit normalization steps and formulas (ΔCt, %Input with dilution factors, ΔΔCt for treated vs control) with the resulting values; and QC context such as RNA integrity/fragment size distribution, antibody lot information, replicate concordance summaries, and any background-binding assessments. These fundamentals enable independent review and re-analysis.
Biological outputs that support interpretation
Look for clear summaries of target-level enrichment differences across matched conditions, with uncertainty estimates or error bars. Region-aware plots-such as %Input bars for Candidate vs Reference regions under Vehicle and Compound-help readers see whether the effect is focused. Explicit interpretation notes that separate expression change from enrichment change improve trust and make the results easier to act on.
Why region annotation and re-analysis-ready files matter
Good reports include the primer sequences, amplicon sizes, transcript/isoform IDs, genome build, approximate amplicon coordinates, and a short rationale for region selection. Analysis-ready tables (CSV/XLSX) and visualization files reduce friction when integrating the result into a broader data package or a methods section. If you plan to scale to discovery, it helps to align file formats and annotation fields with typical downstream inputs so handoff is smooth.
For teams that prefer to outsource execution or reporting standardization, CD Genomics provides MeRIP-qPCR and related m6A profiling services for research use only (RUO) with structured deliverables like the items above; see the scope and example outputs on the MeRIP-qPCR service page under the epigenetics program at CD Genomics (MeRIP-qPCR Services). When your question shifts from single-target confirmation to broader profiling, you can review a concise overview of discovery options and analysis considerations in the MeRIP-seq resources (MeRIP-seq overview and applications).
FAQs About MeRIP-qPCR Single-Gene Validation
Can MeRIP-qPCR show whether a compound reduces m6A on a specific gene?
It can support that interpretation when you choose a plausible enriched region and analyze IP together with input under matched treatment controls. A consistent reduction in normalized enrichment across biological replicates suggests the compound reduces relative m6A capture at that region. Remember that this does not establish mechanism or selectivity; those require additional evidence, as discussed in replication- and input-aware analyses of MeRIP methods published in 2020 and integrated workflows published in 2023.
Is MeRIP-qPCR enough to prove direct inhibition of m6A modification?
No. It supports a change in relative enrichment at the tested target and condition, but it does not, on its own, prove direct target engagement, writer/eraser specificity, or transcriptome-wide selectivity. Consider dose-response, time courses, base-resolution assays, and/or broader profiling when mechanism-level claims are important.
Do I need to measure input RNA as well as IP-enriched RNA?
In most cases, yes. Input provides the expression context that prevents misreading abundance shifts as methylation changes. Reporting %Input or an equivalent input-aware metric keeps the comparison grounded and is consistent with how many teams validate sequencing-derived candidates.
How many targets should I test in a focused validation study?
It depends on the study goal. If the hypothesis is centered on a single, mechanistically important transcript, starting with that one target is reasonable. If your decision requires a sense of breadth or selectivity, add a small comparator set to see whether the effect is focused or widespread before scaling to discovery assays.
When should I move from MeRIP-qPCR to transcriptome-wide m6A profiling?
Usually when the targeted result is promising but you need broader context, mechanism insight, or selectivity assessment. Use your pre-defined expansion criteria-magnitude, consistency, and biological relevance-to decide whether to proceed to MeRIP-seq or to orthogonal site-level assays.
When the Study Is Ready for Technical Discussion
If you have already defined a plausible target region and treatment question, planned matched controls, intend to interpret IP alongside input, and have clear criteria for what outcome would justify expansion, you are likely ready. If only a gene name exists without a region strategy, if your analysis does not separate expression and enrichment, if matched treatment control is missing, or if your intended claim exceeds what the assay can support, refine the design first. Before requesting support, prepare the target region details, treatment and control plan, expected direction of change, approximate sample count, and whether broader follow-up is under consideration if the result is promising.
Editorial note
This article is written as a methods-focused best-practices guide for research teams using MeRIP-qPCR to evaluate treatment-associated changes in relative m6A enrichment at predefined transcript regions. It is intended for technically trained readers and summarizes common design and interpretation practices with supporting peer-reviewed citations.
Authorship and review: Prepared by the CD Genomics epigenetics scientific content team, based on published methods literature and routine assay design considerations for RNA immunoprecipitation workflows.
Scope and limits: MeRIP-qPCR supports region-level, antibody-dependent enrichment comparisons and should be interpreted with matched input RNA, appropriate controls, and biological replication. It does not, by itself, establish base-resolution modification status, absolute methylation fraction, or direct mechanism.
Disclosure: Any mention of CD Genomics services is provided for research use only (RUO) and is included solely as an example of standardized deliverables and reporting practices; it does not change the methodological interpretation boundaries described above.
If you reach the point where targeted evidence is consistent and you're deciding whether to expand, it may help to review a concise overview of transcriptome-wide options, analysis considerations, and reporting scope in a discovery context; a succinct starting point is the MeRIP-seq resource overview under the epigenetics program at CD Genomics (MeRIP-seq overview and applications).
References and further reading
- For regional bias and mechanistic context of m6A distribution near 3' UTRs and stop codons, see the VIRMA study in Molecular Cell (2018) discussing preferential 3'-region methylation (Yue 2018).
- For assay limits, replication, and input-aware interpretation of dynamic changes, see the communication on MeRIP/m6A-seq detection issues and recommendations (Genome Biology/Genome Research, 2020) (McIntyre 2020).
- For integrated discovery-plus-validation logic and normalization-aware comparisons, see the 2023 CSBJ workflow that pairs MeRIP-seq with targeted qPCR validation (Shi 2023).
- For practical qPCR normalization and comparison logic in RIP/MeRIP validations, see NAR Cancer, 2023, on epitranscriptome analysis and validation approaches (Hodara 2023).
- For an applied protocol example of region-level positive/negative contrasts in MeRIP-RT-qPCR, see STAR Protocols, 2022 (Li 2022).