
 Sample Submission Guidelines
Sample Submission Guidelines
What is a genome?
A genome is the complete set of DNA (or RNA in RNA viruses) of an organism. It is sufficient to build and maintain that organism. Each nucleated cell in the body contains this same set of genetic material. In humans, a copy of the entire genome consists of more than 3 billion DNA base pairs. The genome includes both coding regions (genes) and non-coding DNA, probably present in the nucleus, mitochondrion, chloroplast (for plants), and cytoplasm. The central dogma of molecular biology (Figure 1) explains the flow of genetic information within a biological system. It suggests that DNA contains the genetic information needed to make all of our proteins, and that RNA is responsible for carrying this information to the ribosomes. The study of genomes is known as genomics, and the most powerful tool for genomics is the sequencing technology.
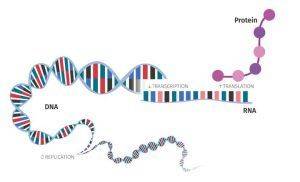
Figure 1. The central dogma of molecular biology.
DNA structure
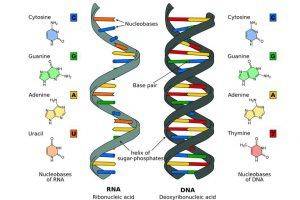
DNA is made up of four types of nucleotides. Each nucleotide contains a phosphate group, a sugar group, and a nitrogen base (adenine, thymine, guanine, or cytosine). Nucleotides are attached together to form a structure called a double helix. The two strands of DNA are antiparallel and are linked by hydrogen bonding based on complementary base pairing. Adenine (A) pairs with thymine (T) via two hydrogen bonds, while guanine pairs with cytosine (C) via three hydrogen bonds. DNA information can tell the genetic relationship and reveal the risk for certain diseases. DNA sequencing can achieve the goals by determining the order of bases and epigenetic patterns. Whole genome sequencing investigates the complete DNA sequence of an organism’s genome at a time, and targeted sequencing can focus on your selected region(s) of interest with boosted sequencing depth and at a reduced cost. And epigenomics is the study of DNA modifications.

Figure 2. DNA structure.
RNA structure
Another type of nucleic acid is RNA, or ribonucleic acid. RNA translates DNA into proteins, and is the genetic material of some prokaryotes and viruses. Unlike DNA, RNA only has one strand and the sugar in RNA is ribose sugar molecules, not deoxyribose in DNA. What’s more, RNA has four bases, A, U, C (uracil), and G. RNA plays leading roles in the cell as structural components, enzymes, and in cell signaling. RNA can be classified into many types based on function, such as mRNA, ribosomal RNA (rRNA), microRNA (miRNA), interfering RNA (siRNA). Both miRNA and siRNA can regulate gene expression by degrading mRNA after transcription.
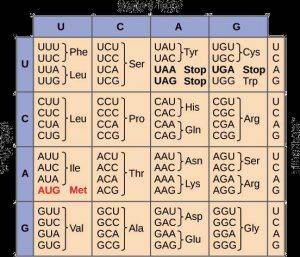
In transcription, the coding sequence is “rewritten” using RNA nucleotides. After some processing steps, these RNA molecules become a messenger RNA (mRNA). mRNA is then translated into polypeptides. Groups of three nucleotides decode amino acids or function as start or stop codons, called genetic codons. RNA sequencing is commonly used to find alternative gene spliced transcripts, post-transcriptional modification, gene mutations, gene fusion, as well as profile gene expression in different groups or treatments.
 |
 |
|
Figure 2. The differences between DNA and RNA. |
Figure 3. Codon table. |