Long-read RNA Sequencing: A Powerful Tool for Analyzing Plant and Animal Transcriptomes
At a glance:
- Overview of Long-read RNA Sequencing
- Applications of Long-read RNA Sequencing in Research
- Future Prospects of long-read RNA Sequencing
- Conclusion
Transcriptome of animals and plants contains all transcription information under specific conditions, which is very important for understanding their growth and development, responding to environmental stress, and the mechanism of disease occurrence and development. By studying the transcriptome, we can reveal the regulatory network of gene expression and provide theoretical support for agricultural breeding, biopharmaceuticals, and ecological protection.
Although the traditional short-reading RNA sequencing is widely used, it is insufficient to deal with complex transcripts (such as long genes, alternative splicing isomers and fusion genes) due to the limitation of reading length. The short reading length makes it difficult to span the whole length of the transcript, which leads to splicing errors, affects the accurate analysis of the structure and function of the transcript, and limits the comprehensive and in-depth study of the plant and animal transcriptome.
Long-read RNA sequencing technology came into being, which can directly read longer RNA sequence fragments, effectively solve the splicing problem of short-reading sequencing, accurately identify transcript isomers, fusion genes and transcription start and end sites, bring new opportunities for the study of plant and animal transcriptome, and promote the development of this field in depth.
This paper introduces long-read RNA sequencing technology, demonstrates its advantages through application cases of plants and animals, and discusses the future prospect of this technology.
Overview of Long-read RNA Sequencing
Long-read RNA sequencing technology is mainly based on single molecule real-time (SMRT) sequencing of PacBio and nanopore sequencing of Oxford Nanopore. PacBio's SMRT sequencing technology uses zero-mode waveguide hole (ZWM) structure to immobilize DNA polymerase at the bottom of ZWM. When deoxyribonucleoside triphosphate (dNTP) enters ZWM and binds to the template chain, it will emit fluorescence signal, and identify the base by detecting the fluorescence color and duration, thus realizing the sequencing of long cDNA fragments generated by RNA reverse transcription. Because the technology is sequenced at the single molecule level, it is not interfered by other molecules, and it can accurately obtain the sequence information of long fragments, which provides a strong support for analyzing the structure of complex transcripts.
Oxford Nanopore's nanopore sequencing is to let RNA or cDNA molecules pass through the protein pore at nanometer level. When the molecules pass through, the ion current in the pore will change, and different bases have different effects on the ion current, so as to identify the base sequence. Its advantage lies in that RNA molecules can be sequenced directly without reverse transcription, which avoids the deviation introduced by reverse transcription and can more truly reflect the characteristics of original RNA, including RNA modification and other information.
Applications of Long-read RNA Sequencing in Research
With the advantage of long reading length, long-read RNA sequencing technology of animals and plants can accurately determine full-length transcripts, provide important technical support for in-depth analysis of transcription regulation mechanism, and show significant application value and broad prospects in many fields.
Practical Application in Plants
Direct RNA Sequencing (DRS) is a long-read RNA sequencing technology based on Nanopore platform, which overcomes many limitations faced by traditional short-reading and long-read RNA sequencing, such as reading length limitation and PCR amplification deviation. DRS can accurately detect the original full-length transcripts and analyze the complexity and diversity of plant transcriptome from many aspects (new isomers, poly(A) tail and RNA modification, etc.).
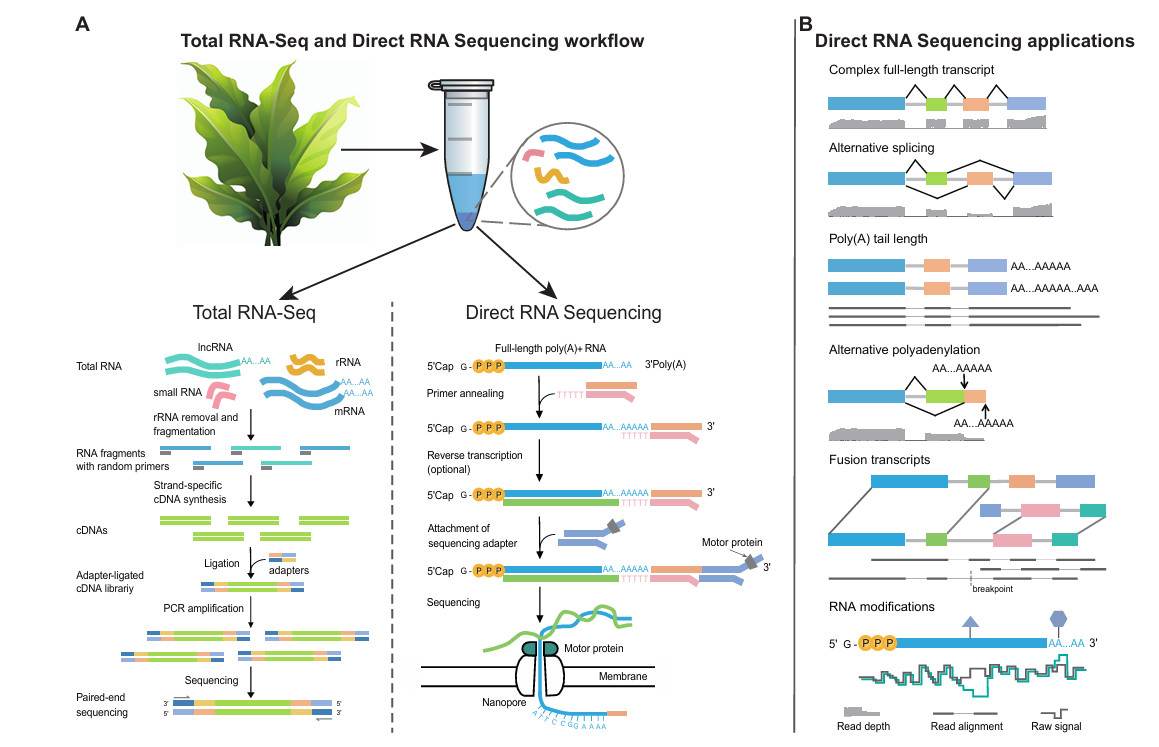 Overview of the DRS protocol and its applications in plants compared with total RNA-seq (Zhu et al., 2024)
Overview of the DRS protocol and its applications in plants compared with total RNA-seq (Zhu et al., 2024)
Study on Complex Plant Transcriptome
Full-length transcription is an ideal tool for gene model prediction and new gene identification, while DRS is especially suitable for discovering new complex isomers and analyzing the dynamic changes of transcriptome that are difficult to handle with short-reading RNA-seq. Through DRS technology, researchers have found a large number of new transcripts in many plants, such as 22,360 in Phyllostachys pubescens, 16,432 in Platanus acerifolia, 578 in artichoke, 110,888 in strawberry and 38,500 in Arabidopsis thaliana. These new transcripts have significantly expanded the scope of the genome. In addition, DRS can also analyze the wide distribution of new transcripts produced by transposable elements (TEs) inserting introns in plants.
The study of DRS in polyploid plants also shows obvious advantages, such as finding different alternative splicing events between hexaploid and decaploid in Platanus acerifolia. DRS is also used to compare alternative splicing isomers between hybrids and their diploid parents, revealing important information related to the adaptive evolution of polyploid. In a word, DRS technology shows great ability in analyzing the complexity of plant transcriptome, which provides a unique perspective for understanding the biological role of full-length transcripts in plant development.
Detection of lncRNAs and circRNAs
LncRNAs in plants participate in biological processes such as chromatin remodeling and transcription regulation through various mechanisms. DRS can identify new lncRNAs with complex structure and difficult to detect by short reading length technology. For example, 2,613 to 3,389 new lncRNAs were found in nine citrus species, and 796 new lncRNAs were identified in wheat, of which 29% contained TE insertions, which highlighted the ability of DRS to identify lncRNAs in polyploid and repetitive plant genomes. In addition, DRS is also used to detect circRNAs. Although there are technical challenges, these covalently closed circular structures can be effectively identified by special enrichment and reverse transcription methods, such as CIRI-long. For example, 470 circRNAs were identified in Phyllostachys pubescens, indicating that DRS has potential in identifying large circRNAs.
Fusion Transcript Identification
Fusion transcript is a hybrid molecule formed by the fusion of RNA products of two originally independent genomic regions or genes. These fusion events can be caused by genome rearrangement at DNA level, or by transcription splicing, transcription read-through and cis-splicing at RNA level. Compared with the short reading length method, DRS has a lower false positive rate in detecting fusion events and can detect full-length fusion transcripts. Although the research on the function of fusion transcripts in plants is limited at present, it has been revealed that they not only exist at the level of DNA and RNA, but also show low expression level and tissue specificity. For example, a new type of fusion transcript was identified in Arabidopsis thaliana by DRS technology, and it was found that transposable elements might promote the formation of fusion transcripts in grapes.
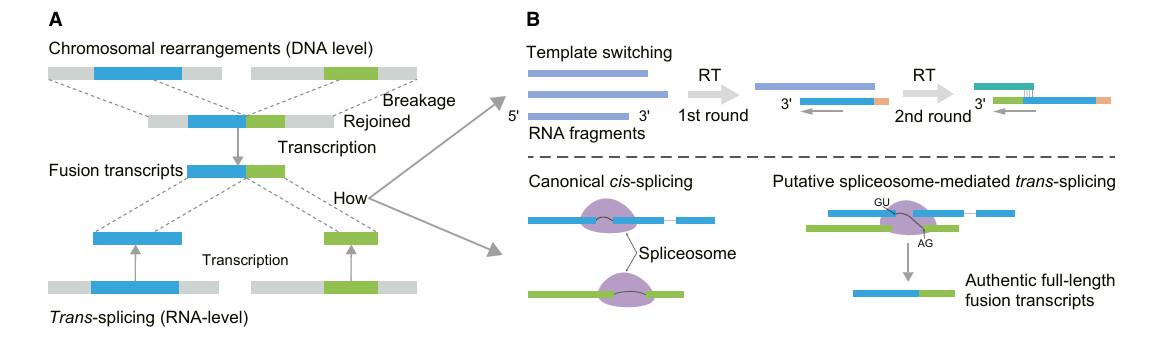 Types of fusion transcripts and their presumptive biogenesis (Zhu et al., 2024)
Types of fusion transcripts and their presumptive biogenesis (Zhu et al., 2024)
Functional Characteristics of Poly(A) Tail
Poly(A) tail is an important part of the 3' end of RNA molecule, and its length changes affect the output, stability and translation efficiency of RNA. DRS technology can capture full-length transcripts and reveal the changes of the tail length of poly(A) in different tissues. In addition, the tail length of poly(A) is gene-specific, and longevity mRNA usually has a short tail. Although the tail length distribution of different species is different, the tail length patterns of homologous genes are similar, indicating that poly(A) is conservative in the evolution process.
Variable polyadenylation (APA) increases the diversity of transcripts by changing the 3' splicing site, and has an important impact on the fate of RNA. DRS data revealed a large number of new APA events, such as the discovery of 109,880 APA loci in Arabidopsis thaliana. APA plays an important regulatory role in plant development and can respond to environmental signals, such as poplar tends to use remote APA sites under drought stress. Compared with traditional complex methods, DRS provides a simple and effective method for studying the dynamic changes of polyadenylation in plants.
RNA Modification Detection
DRS can detect RNA modification quickly and accurately without additional chemical treatment, which is a great progress compared with antibody-based technology. In eukaryotes, there are more than 170 reversible chemical modifications on RNA, which constitute the epigenome and participate in the regulation of gene expression. DRS can distinguish modified and unmodified bases, and detect many types of RNA modifications, including common m6A and m5C and other rare modifications, which affect RNA splicing, stability, movement and translation efficiency in plants.
With the development of DRS technology, RNA modification can be detected efficiently, such as the recognition accuracy of m6A single base modification is 97%. In addition, DRS also revealed the relationship between modification and polyadenylation tail. For example, m6A-dependent poly(A) tail shortening will affect the stability of mRNA. In Arabidopsis thaliana and rice, DRS helps to analyze the functional mechanisms of m5C and m6A modifications under different conditions. For example, m5C plays an important role in long-distance mRNA movement, while m6A modification plays a key role in translation efficiency and abiotic stress response.
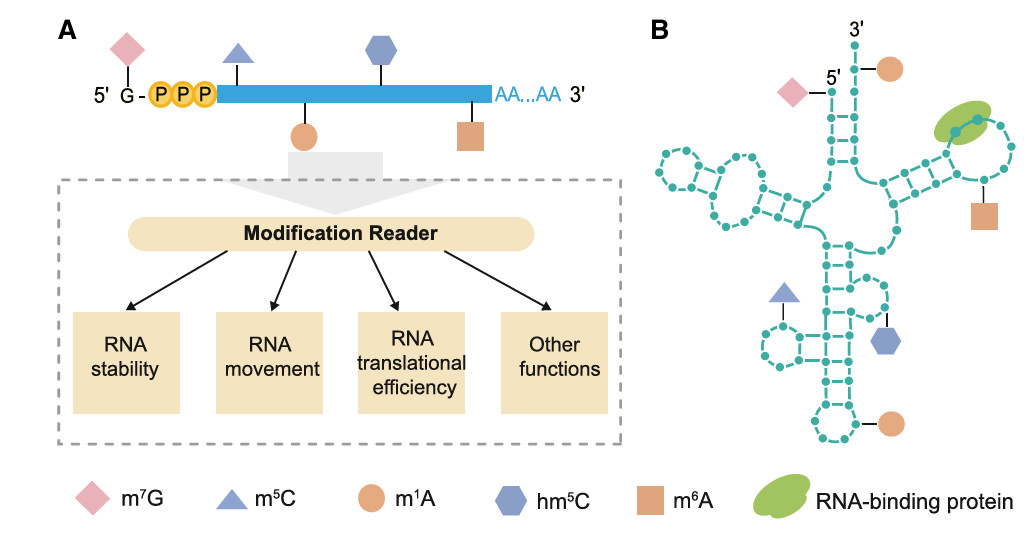 Multiple types of RNA modifications (Zhu et al., 2024)
Multiple types of RNA modifications (Zhu et al., 2024)
Animal-based Practical Applications
At present, the animal DRS technology is mainly applied to mice, cattle, soft-shelled turtle, bees, nematodes and other species, among which the research on mouse DRS is the most, mostly focusing on using different mouse models to reveal the occurrence mechanism of specific diseases and the development law of certain organs.
Development Mechanism of Bovine Testis
Bovine testis tissues at three different developmental stages were sequenced by Direct RNA. A total of 56,560 coding genes were identified, including 97,802 transcripts (28,999 known transcripts and 68,803 new transcripts). The median length of the optimized transcript is 3,237 bp, which is longer than the annotation length in Btau_5.0.1. DEG and DEI co-expressed between TY 0-TY 1 and TY 0-TY 2 accounted for 79.43% and 78.87%. Most DEG and DEI are involved in testicular development and spermatogenesis. The results of WGCNA analysis showed that all gene modules were significantly related to testicular morphology and semen phenotypic traits, and hub gene could regulate the expression level through different AS events, thus affecting testicular weight.
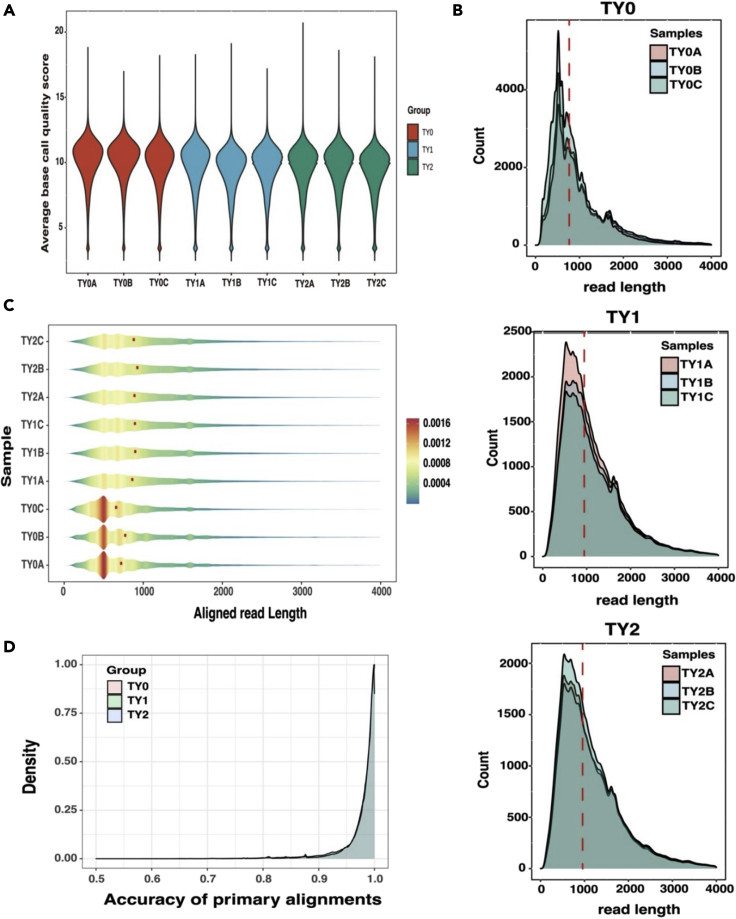 Summary statistics of Oxford Nanopore Technologies (ONT) data (Liu et al., 2023)
Summary statistics of Oxford Nanopore Technologies (ONT) data (Liu et al., 2023)
The average length of Poly(A) of the Top20 hub gene increases with the development of testis. Only three pivotal genes (MAEL, ROPN1L and SRATA6) showed DAS events at all developmental stages, and MAEL showed the highest incidence. A total of three AS events (including A3, A5 and SE) occurred simultaneously on MAEL's transcript 2544.t2, and these events were significantly different in different stages of testicular development. There are abundant m5C sites in the splicing sites of these DAS events, and the number of m5C sites in TY1 and TY2 groups is significantly higher than that in TY0 group, no matter what kind of DAS occurs. The results showed that m5C-mediated selective shearing event was a potential molecular mechanism to regulate testicular development and spermatogenesis in Simmental bull.
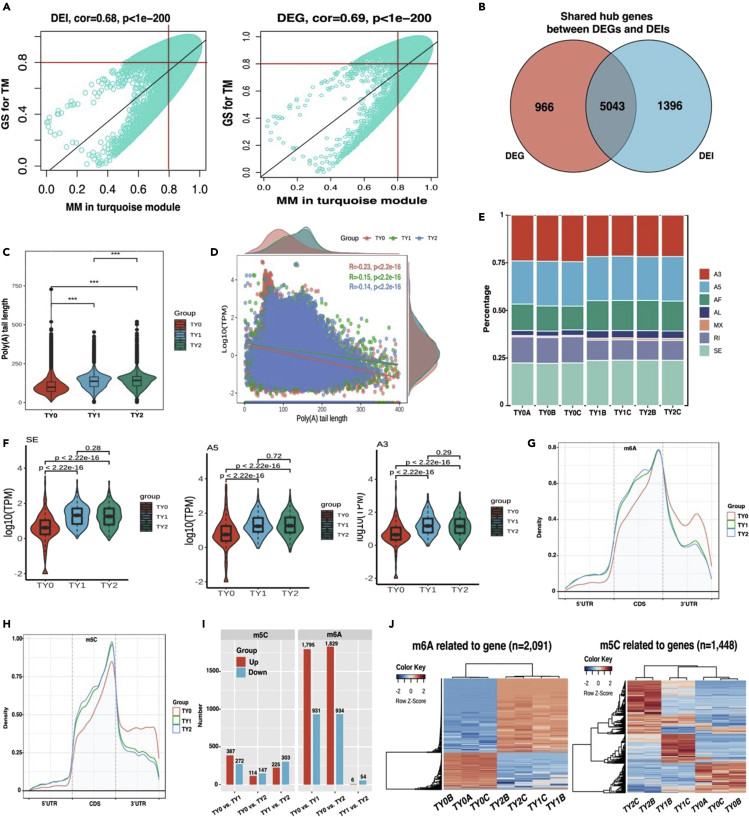 WGCNA, poly(A) tails, alternative splicing, and RNA modifications analysis reveal the hub genes related to testis weight (Liu et al., 2023)
WGCNA, poly(A) tails, alternative splicing, and RNA modifications analysis reveal the hub genes related to testis weight (Liu et al., 2023)
Revealing B cell Prmt5 and Tumor Progression
By DRS sequencing of RNA extracted from Prmt5cko and control mice B cells, 845 differential DEIs and 707 differential DEGs were found. Up-regulated genes are mainly concentrated in cell cycle, cell response to IFN-γ, apoptosis and response to tumor cell pathway, while down-regulated genes are concentrated in mRNA processing and HIF signal pathway. The efficiency of alternative splicing in B cells is regulated by Prmt5, and the deletion of Prmt5 mainly damages the splicing of introns. Transcripts affected by alternative splicing events (ASE) are enriched in pathways related to ribosome, mRNA processing, cell cycle and adaptive immune system. Compared with the control group, transcripts with long Poly(A) tail are enriched in RNA metabolism, RNA processing, cell cycle and BCR pathway signal transduction.
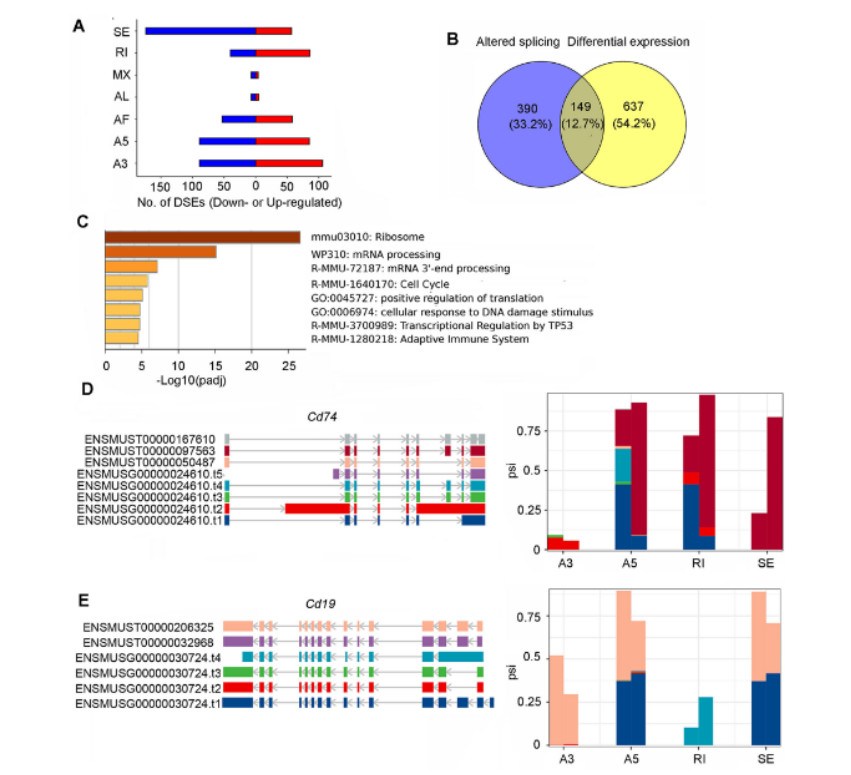 Loss of Prmt5 activity alters the splice variant landscape and disrupts gene expression in B cells (Zhou et al., 2023)
Loss of Prmt5 activity alters the splice variant landscape and disrupts gene expression in B cells (Zhou et al., 2023)
The expression of isoforms modified by m6A decreased in Prmt5cko group. Up-regulated genes modified by m6A are mainly enriched in cancer pathway cell migration, while down-regulated genes are mainly enriched in B cell receptor signaling pathway. B cells of Prmt5cko mice attracted a large number of CD4+ and CD8+ T cells in vitro. The high level of infiltrating T cells in Prmt5cko group is not due to inducing Ccr4 expression, but due to the high level of Ccl22 produced by B cells in Prmt5cko group, which indicates that Prmt5 deletion of tumor infiltrating B cells plays an important role in preventing tumor development.
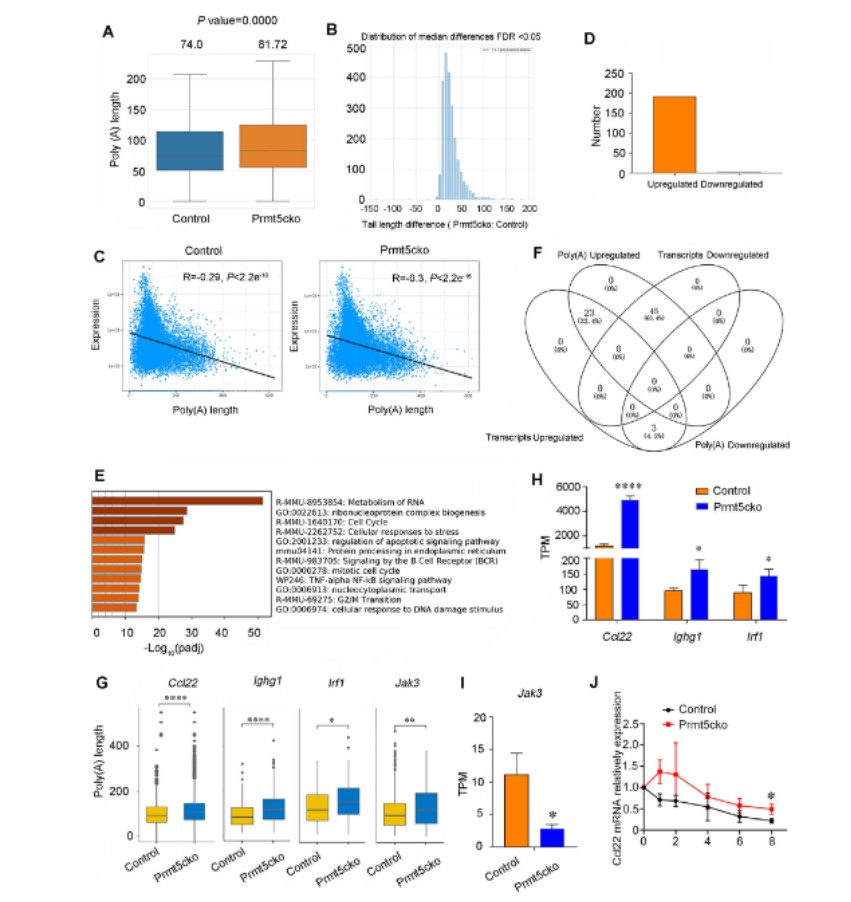 Correlation between poly(A) tail length and DEI expression in Prmt5-deficient B cells (Zhou et al., 2023)
Correlation between poly(A) tail length and DEI expression in Prmt5-deficient B cells (Zhou et al., 2023)
Future Prospects of long-read RNA Sequencing
Long-read RNA sequencing can break through the limitations, directly read complete RNA and reveal deep biological information. With the development of technology, its future application prospects in precision medicine, biodiversity research and other fields are extremely broad.
Technological Innovation Trend
In terms of improving accuracy, PacBio HiFi sequencing has been able to improve the accuracy of single molecule sequencing to more than 99%. In the future, it is expected to further reduce the error rate by optimizing the base recognition algorithm and improving the fluorescence labeling chemistry, so that the accuracy of long-read RNA sequencing will be in line with that of short-reading sequencing.
The upgrading of instruments and equipment will be the key to improve the flux. There may be more integrated and large-scale sequencing systems in the future. At the same time, the application of microfluidic technology will greatly increase the sample processing capacity and realize more Qualcomm-sized long-read RNA sequencing.
In terms of cost reduction, with the maturity of technology and large-scale production, the cost of sequencing reagents will gradually decrease. In addition, the combination of more efficient data processing algorithms and cloud computing can also reduce the hardware resources required for data analysis and reduce the cost of long-read RNA sequencing as a whole.
Research and Application Expansion
In the field of animal and plant genetics and breeding, long-read RNA sequencing can be used to mine transcript markers closely related to excellent traits. In rice breeding, by sequencing long-read RNA of different rice varieties at different growth stages, the key transcripts and their isomers that regulate rice yield, quality and stress resistance can be accurately identified, which can provide more accurate targets for molecular marker-assisted breeding and accelerate the cultivation of new rice varieties with high yield, high quality and stress resistance.
In biopharmaceuticals, long-read RNA sequencing can find new drug targets and mechanisms. Taking cancer treatment as an example, tumor-specific fusion transcripts and abnormal alternative splicing events can be identified by long-read RNA sequencing of tumor tissues and normal tissues. These transcripts may encode unique protein and become potential drug targets.
In the field of ecological protection, long-read RNA sequencing can be used to monitor the transcription response of animals and plants to environmental changes. When studying the impact of climate change on forest ecosystem, sequencing the transcriptome of different tree species under different climatic conditions can reveal the molecular mechanism of trees' response to environmental stresses such as temperature rise and drought, and find the key transcriptional regulatory network, which provides theoretical support for formulating scientific ecological protection and restoration strategies.
Conclusion
By long-read RNA sequencing, we can deeply explore the transcription regulatory network in the process of animal and plant growth and development, and analyze its molecular mechanism in response to environmental changes and disease occurrence and development, which has opened up new paths for agricultural breeding, biopharmaceuticals, ecological protection and other fields.
Looking forward to the future, with the continuous innovation of sequencing technology and the continuous optimization of analysis methods, long-read RNA sequencing is expected to overcome the existing problems and be deeply integrated with multi-omics technology, providing more comprehensive and accurate technical support for animal and plant science research, releasing greater potential and value in life sciences, and becoming the core driving force to promote the development of related fields.
References
- Zhu X T, Pablo S J, Ning X T., et al. "Direct RNA sequencing in plants: Practical applications and future perspectives." Plant Comm. 2024 5: 101064 https://doi.org/10.1016/j.xplc.2024.101064
- Liu S, Ma X, et al. "MAEL gene contributes to bovine testicular development through the m5C-mediated splicing." iScience. 2023 26(2): 105941 https://doi.org/10.1016/j.isci.2023.105941
- Zhou B, Chen N., et al. "Prmt5 deficient mouse B cells display RNA processing complexity and slower colorectal tumor progression." Eur J Immunol. 2023 53(10): e2250226 https://doi.org/10.1002/eji.202250226
For research purposes only, not intended for personal diagnosis, clinical testing, or health assessment